Hive 总结
Hive 总结
总结人:XXX 2020.04.29
0.补充
0.1 什么是hive
1. Hive:由Facebook开源用于解决'海量结构化日志'的数据统计'工具'。
2. Hive是基于Hadoop的一个'数据仓库工具',可以将结构化的数据文件'映射'为一张表,并提供类SQL查询功能。
3. '本质':将HQL转化成MapReduce程序
4. '原理介绍'
(1)Hive处理的数据存储在HDFS
(2)Hive分析数据底层的实现是MapReduce
(3)执行程序运行在Yarn上0.2 优缺点
-- 1. 优点:
1. 操作接口采用类SQL语法,提供快速开发的能力(简单、容易上手)。
2. 避免了去写MapReduce,减少开发人员的学习成本。
3. Hive的执行延迟比较高,因此Hive常用于数据分析,对实时性要求不高的场合。
4. Hive优势在于处理大数据,对于处理小数据没有优势,因为Hive的执行延迟比较高。
5. Hive支持用户自定义函数,用户可以根据自己的需求来实现自己的函数。
-- 2. 缺点
1. Hive的HQL表达能力有限
2. 迭代式算法无法表达
3. 数据挖掘方面不擅长,由于MapReduce数据处理流程的限制,效率更高的算法却无法实现。
4. Hive的效率比较低
(1)Hive自动生成的MapReduce作业,通常情况下不够智能化
(2)Hive调优比较困难,粒度较粗0.3 Hive架构原理
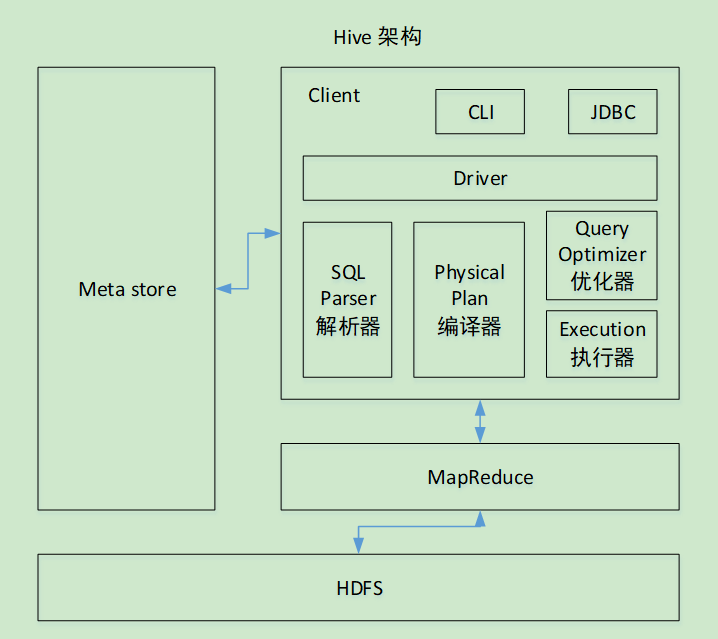
-- 1. 用户接口:Client
CLI(command-line interface)、JDBC/ODBC(jdbc访问hive)、WEBUI(浏览器访问hive)
-- 2. 元数据:Metastore
元数据包括:
a、表名
b、表所属的数据库(默认是default)
c、表的拥有者
d、列/分区字段
e、表的类型(是否是外部表)、
f、表的数据所在目录等;
'默认存储在自带的derby数据库中,推荐使用MySQL存储Metastore'
-- 3. Hadoop
使用HDFS进行存储,使用MapReduce进行计算。
-- 4. 驱动器:Driver
1. '解析器'(SQL Parser):将SQL字符串转换成抽象语法树AST,这一步一般都用第三方工具库完成,
比如antlr;对AST进行语法分析,比如表是否存在、字段是否存在、SQL语义是否有误。
2. '编译器'(Physical Plan):将AST编译生成逻辑执行计划。
3. '优化器'(Query Optimizer):对逻辑执行计划进行优化。
4. '执行器'(Execution):把逻辑执行计划转换成可以运行的物理计划。对于Hive来说,就是MR/Spark。0.4 hive与数据库的比较
由于 Hive 采用了类似SQL 的查询语言 HQL(Hive Query Language),因此很容易将 Hive 理解为数据库。其实从结构上来看,Hive 和数据库除了拥有类似的查询语言,再无类似之处
-- 1. 查询语言
hive有类似sql的hql查询语言
-- 2. 数据更新
1. hive针对数据仓库而设计,适合读多写少的场景
2. mysql的数据需要经常进行修改。
-- 3. 执行延迟
1. hive没有索引 + 基于mr计算,延迟性高;
2. 这个低是有条件的,即数据规模较小,当数据规模大到超过数据库的处理能力的时候,Hive的并行计算显然能体现出优势
-- 4. 数据规模
1. 支持大数据规模的数据0.5 tez引擎
1. 'mr引擎':每个任务及任务之间都需要落盘
2. 'Tez引擎':可以将多个有依赖的作业转换为一个作业,这样只需写一次HDFS,且中间节点较少,从而大大提升作业的计算性能。
一、HiveJDBC客户端基本操作
1.1 HvieJDBC的登入与退出
-- 方式一:使用beeline方式
访问方式:beeline -u jdbc:hive2://hadoop102:10000 -n lianzp
退出方式:!quit 、!exit 、 ctrl + c
前提:mysql服务和hiveservice2服务一定要启动
-- 方式二: 使用hive的方式
访问方式:hive
退出方式:quit; exit;1.2 Hive常用的交互命令
“-e” 不进入hive的交互窗口执行sql语句**
“-f” 执行脚本中sql语句**
1.3 Hive数据类型
- 基本数据类型
| Hive数据类型 | Java数据类型 | 长度 | 例子 |
|---|---|---|---|
| TINYINT | byte | 1byte有符号整数 | 20 |
| SMALINT | short | 2byte有符号整数 | 20 |
| INT | int | 4byte有符号整数 | 20 |
| BIGINT | long | 8byte有符号整数 | 20 |
| BOOLEAN | boolean | 布尔类型,true或者false | TRUE FALSE |
| FLOAT | float | 单精度浮点数 | 3.14159 |
| DOUBLE | double | 双精度浮点数 | 3.14159 |
| STRING | string | 字符系列。可以指定字符集。可以使用单引号或者双引号。 | ‘now is the time’ “for all good men” |
| TIMESTAMP | 时间类型 | ||
| BINARY | 字节数组 |
重点关注:int,string,double,bigint ;
使用注意事项:在sql中需要指定字段的长度,而在hive中不需要,可以理解为可变参数 ;
数据类型的字节数:
byte short int long float double char 1 2 4 8 4 8 2 其中float的取值范围比long还要大。
集合数据类型
数据类型 描述 语法示例 STRUCT 和c语言中的struct类似,都可以通过“点”符号访问元素内容。例如,如果某个列的数据类型是STRUCT{first STRING, last STRING},那么第1个元素可以通过字段.first来引用。 struct()例如struct<street:string, city:string> MAP MAP是一组键-值对元组集合,使用数组表示法可以访问数据。例如,如果某个列的数据类型是MAP,其中键值对是’first’->’John’和’last’->’Doe’,那么可以通过字段名[‘last’]获取最后一个元素 map()例如map<string, int> ARRAY 数组是一组具有相同类型和名称的变量的集合。这些变量称为数组的元素,每个数组元素都有一个编号,编号从零开始。例如,数组值为[‘John’, ‘Doe’],那么第2个元素可以通过数组名[1]进行引用。 Array()例如array <string>
创建表的实例:
create table if not exists test(
name string,
friends array<string>, /*--数组的格式--*/
children map<string, int>, /*--集合的格式--*/
address struct<street:string, city:string>/* --Struct格式-- */
)
row format delimited fields terminated by ','
/* 行 格式 划分属性 以‘,’分割 ,统称为列分割符*/
collection items terminated by '_'
/*集合(数组,集合,Struct) 多个元素之间以‘_’ 分割,则要求所有的数据的格式均是一样的*/
map keys terminated by ':'
/*指明集合中key和value以‘:’ 进行分割*/
lines terminated by '\n';
/*行数据,以换行符进行分割*/获取集合中属性的方式:
* 数组:使用索引的方式:字段名[index]
*
* 集合:使用key的值获取:字段名[key的值]
*
* Struct:使用:字段.属性值1.4 类型转化
隐式类型转换规则
任何整数类型都可以隐式地转换为一个范围更广的类型,如TINYINT可以转换成INT,INT可以转换成BIGINT;
所有整数类型、FLOAT和STRING类型都可以隐式地转换成DOUBLE;
TINYINT、SMALLINT、INT都可以转换为FLOAT;
BOOLEAN类型不可以转换为任何其它的类型。
CAST操作显示进行数据类型转换
-- 示例: select cast ('1' as int) + 3 ; /* 4 */ select '1' + 3 ; /* 4.0 */
二、DDL数据定义
2.1 数据库操作
2.1.1显示和查询数据库与表信息
1.显示数据库
show databases;
2.切换数据库
use 数据库名;
3.查询数据库详细信息
desc database [extended] 数据库名
4.查询表的详细信息
desc [formatted] 表名2.1.2 创建数据库
CREATE DATABASE [IF NOT EXISTS] database_name
[COMMENT database_comment]
[LOCATION hdfs_path]
[WITH DBPROPERTIES (property_name=property_value, ...)];实例:
1.create database db_hive;
2.create database if not exists db_hive;
/* 加上 if not exists 后,当该数据库已存在时,不抛异常,也不做创建数据库的操作*/
3.create database db_hive2 location '/db_hive2.db';
/*指定数据创建时,在hdfs上的路径,如果没有此操作,则默认的路径为:/user/hive/warehouse/数据库名*/2.1.3 删除数据库
1.删除空的数据库(何为空的数据库?指该数据中没有表)
drop database db_hive2 ;
2.当数据库不存在时,避免抛异常
drop database if not exists db_hive2 ;
3.当数据库不为空时,加上cascade进行删除
drop database if not exists db_hive2 cascade ;2.2 表的操作
2.2.1 建表语法
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name
[(col_name data_type [COMMENT col_comment], ...)]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
[CLUSTERED BY (col_name, col_name, ...)
[SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
[ROW FORMAT row_format]
[STORED AS file_format]
[LOCATION hdfs_path]
[TBLPROPERTIES (property_name=property_value, ...)]
[AS select_statement]各个参数说明:
EXTERNAL :表示外部表,在删除表时,只会删除mysql中的元数据,在hdfs的真实数据不会被删除,如果没EXTERNAL ,则删除表的时候,元数据和真实数据均为被删除。
IF NOT EXISTS :当表存在时,添加此操作,则不会抛异常,同时也不会执行建表操作。
COMMENT :字段或表的注释;
PARTITIONED BY : 分区**
(后面详细讲)**;CLUSTERED BY : 分桶**(后面详细讲)**;
SORTED BY :文件在hdfs的存储格式 ,存储的方式有:SEQUENCEFILE(二进制序列文件)、TEXTFILE(文本)、RCFILE(列式存储格式文件)
如果文件数据是纯文本,可以使用STORED AS TEXTFILE。如果数据需要压缩,使用 STORED AS SEQUENCEFILE;
ROW FORMAT row_format :列分割符;
LOCATION hdfs_path:指定表在HDFS上的存储位置;默认为当前库下。
AS select_statement :建表时进行加载数据,通过as后面的查询语句。
2.2.2 管理表与外部表
区别:
1.管理表:也称内部表,当删除管理表时,hdfs中的数据和mysql中的元数据均会被删除 -- 控制表的生命周期
2.外部表:当删除管理表时,hdfs中的数据不会被删除,mysql中的元数据会被删除 -- 不能控制表的生命周期
在实战过程中,我们一般都是使用外部表。内外部表的定义、查看和转换
1.定义:
创建表单时,加上 external 关键字则表示为外部表。
2.查看:
通过 desc formatted 表名 。
3.转换:
alter table 表名 set tblproperties('EXTERNAL'='TRUE');
注意事项:
a、TRUE : 转换为外部表;
b、FALSE : 转换为内部表;
c、('EXTERNAL'='TRUE')和('EXTERNAL'='FALSE')为固定写法,均需要大写!2.2.3 修改表
- 重命名表
-- 语法:
alter table 旧表名 rename to 新表名 ;
-- 示例:
alter table dept_partition2 rename to dept_partition3;- 更新列
-- 语法:
alter table 表名 change 旧列名 新列名 数据类型
-- 示例:
alter table emp change ename naem string first deptno;- 增加列
-- 语法:
alter table 表名 add 列名 数据类型 [字段注释] [first / after 列名]
-- 示例:
alter table emp add loc string ;- 删除表
-- 语法:
drop table 表名
-- 示例:
drop table emp ;三、DML 操作
注意事项:
当导入数据时,如果加载本地的文件,并是将数据加载到有分区和分桶表的hive表中时,因为此导入数据的过程会跑mr程序,该本地文件需要在所有节点都需要,不然会报文件不存在异常。3.1 数据的导入
3.1.1 方式一
- 使用load
-- 语法:
load data [local] inpath '数据的路径' [overwrite] into table 表名 [partition (分区字段 = value1) (分区字段 = value2)]
-- 说明:
local : 如果使用了,则'数据的路径'写linux本地的路径;
如果未使用,则'数据的路径'写hdfs上的路径;
partition (分区字段 = value1) :表示数据上传到哪一个分区,后面详细介绍。
overwrite : 表示覆盖写。
-- 示例:
本地 : load data local inpath '/opt/module/hive/datas/emp' into table emp;
hdfs : load data inpath '/user/hive/warehouse/emp' into table emp;3.1.2 方式二
- 通过查询语句向表中进行添加
-- 语法:
1) insert into table 表名 select 字段 from 表名; -- 追加的方式,原数据不会丢失
2) insert overwrite table 表名 select 字段 from 表名; -- 覆盖原数据的方式,原数据被覆盖
3) insert into table 表名 select 字段 from 表名 partition (分区字段 = Value); 多分区的插入模式
-- 示例:
1) insert into table emp select id ,name from emp1;
2) insert overwrite table emp select id ,name from emp1;
3) insert into table emp select id ,name from emp1 partition (month = '2020-02-04');3.1.3 方式三
- 创建表并使用查询语句加载数据(As Select)
-- 语法:
建表语句 + as + 查询语句
-- 示例:
create [external] table [if not exists] emp (
id int ,
name string
)
row format delimited fields terminated by '\t'
as select id , name from emp1;3.1.4 方式四
- 创建表时使用location的方式
-- 语法:
建表语句 + location + 'hdfs数据路径'
-- 说明:
数据路径:只能是hdfs上的路径,当该路径是一个目录时,则表示加载该文件夹下的所有文件
-- 示例:
create [external] table [if not exists] emp (
id int ,
name string
)
row format delimited fields terminated by '\t'
location '/user/hive/warehouse/emp' ;3.1.5 方式五
- 使用import方式
注意:必须使用export的方式导出以后(导出了元数据和真实数据),再使用import进行导入。
-- 示例:
import table student2 from '/user/hive/warehouse/export/student'3.2 数据的导出
- 说明:数据的导出的方式,使用的情况很少。
3.2.1 方式一
- insert 方式
-- 语法:
insert overwrite [local] directory '输出文件路径' [row format delimited fields terminated by '分割符'] 查询语句
-- 说明:
overwrite :overwrite 是覆盖原文件的数据写入
[local] :加它,表示导出到本地,不加,则表示导出到hdfs上
'输出文件路径' : 配合local来的,加了local,则写本地linux路径,不加,则写hdfs路径
[row format delimited fields terminated by '分割符'] :表示文件输出的格式
-- 示例:
-- 导入到本地
1)insert overwrite local directory '/opt/module/hive/datas/export/student' select * from student;
-- 导出到本地,并指定导出的行数据的分割符
2)insert overwrite local directory '/opt/module/hive/datas/export/student1' ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' select * from student;
-- 导出到hdfs上,并指定导出的行数据的分割符
3)insert overwrite directory '/user/lianzp/student2'ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' select * from student;3.2.2 方式二
- hadoop 的shell命令
-- 语法:
hdfs dfs -get hdfs数据的输出路径 linux输入路径3.2.3 方式三
- hive 的shell命令
-- 语法:
hive -e 查询语句 > linux输入路径3.2.4 方式四
- export的方式
说明:export 和 import 主要用于两个hadoop 平台集群之间的hive表迁移。
-- 语法:
export table 表名 to '文件输出路径' -- 此路径为hdfs路径3.2.5 方式五
- Sqoop 导出 -- > 后续有课程单独讲解
3.3 清除表中数据
- 使用 truncate
-- 语法:
truncate table 表名 ;四、查询
4.1 关键词的总结
-- 建表:
1) partitioned by :分区表
2)clustered by : 分桶表
-- 查询:
1) order by : 全排序
2) distribute by : 查询中做分区
3) sort by : 查询中每个MapReduce内部排序
4) cluster by : 查询中做分区排序
-- 窗口函数:
1) partition by :窗口函数中做分区
2) order by :窗口函数中做排序4.2 sql执行的顺序
1. from ;
2. on ;
3. join ;
4. where ; -- 不能使用列的别名
5. group by ; -- 不能使用列的别名
6. having ; -- 可以使用列的别名
7. select ;
8. distinct ;
9. order by ; -- 可以使用列的别名
10. limit ; -- 可以使用列的别名
注意事项: 表名一旦使用了别名,所有的位置均需使用表的别名。4.3 查询语法
-- 语法:
SELECT [ALL | DISTINCT] select_expr, select_expr, ...
FROM table_reference
[WHERE where_condition]
[GROUP BY col_list]
[ORDER BY col_list]
[CLUST BY col_list
| [DISTRIBUTE BY col_list] [SORT BY col_list]
]
[LIMIT number]
-- 说明:
DISTINCT :去重;
CLUST BY col_list4.4 基本查询
4.4.1 全表和特定列查询
-- 语法:
select * from 表名 ; -- 全表查询
select 列名1、列名2 from 表名 ; -- 特定列查询4.4.2 别名
定义: 在查询中紧跟列名,也可以在列名与别名之间加as;
注意事项:
1)在hive中,中文的别名使用 一对 `` 来注释;
2)as 一般可以省略 ;
3) where 、 group by 后面不能使用列的别名;
4)having 、order by 、limit 可以使用列的别名 ;4.4.3 算术运算符
| 运算符 | 描述 |
|---|---|
| A+B | A和B 相加 |
| A-B | A减去B |
| A*B | A和B 相乘 |
| A/B | A除以B |
| A%B | A对B取余 |
| A&B | A和B按位取与 |
| A|B | A和B按位取或 |
| A^B | A和B按位取异或 |
| ~A | A按位取反 |
4.4.4 常用函数
1) c求和 : sum();
2) 求平均数 : avg () ;
3) 求最大值 : max();
4) 求最小值 : min();
5) 求个数 : count();
-- 说明:
1) count():不计算null值;
2) avg () : 计算平均数时,分母也是不计算null个数的;
3) 所以: avg (字段) = sum (字段) / count(字段),因此我们在计算一些列的平均值时,一般使用count(*)或者是count(1);4.4.5 Where 语句
1) 条件的筛选;
2) 紧跟from后面。4.4.6 比较运算符
| 操作符 | 支持的数据类型 | 描述 |
|---|---|---|
| A=B | 基本数据类型 | 如果A等于B则返回TRUE,反之返回FALSE |
| A<=>B | 基本数据类型 | 如果A和B都为NULL,则返回TRUE,如果一边为NULL,返回False |
| A<>B, A!=B | 基本数据类型 | A或者B为NULL则返回NULL;如果A不等于B,则返回TRUE,反之返回FALSE |
| A<B | 基本数据类型 | A或者B为NULL,则返回NULL;如果A小于B,则返回TRUE,反之返回FALSE |
| A<=B | 基本数据类型 | A或者B为NULL,则返回NULL;如果A小于等于B,则返回TRUE,反之返回FALSE |
| A>B | 基本数据类型 | A或者B为NULL,则返回NULL;如果A大于B,则返回TRUE,反之返回FALSE |
| A>=B | 基本数据类型 | A或者B为NULL,则返回NULL;如果A大于等于B,则返回TRUE,反之返回FALSE |
| A [NOT] BETWEEN B AND C | 基本数据类型 | 如果A,B或者C任一为NULL,则结果为NULL。如果A的值大于等于B而且小于或等于C,则结果为TRUE,反之为FALSE。如果使用NOT关键字则可达到相反的效果。 |
| A IS NULL | 所有数据类型 | 如果A等于NULL,则返回TRUE,反之返回FALSE |
| A IS NOT NULL | 所有数据类型 | 如果A不等于NULL,则返回TRUE,反之返回FALSE |
| IN(数值1, 数值2) | 所有数据类型 | 使用 IN运算显示列表中的值 |
| A [NOT] LIKE B | STRING 类型 | B是一个SQL下的简单正则表达式,也叫通配符模式,如果A与其匹配的话,则返回TRUE;反之返回FALSE。B的表达式说明如下:‘x%’表示A必须以字母‘x’开头,‘%x’表示A必须以字母’x’结尾,而‘%x%’表示A包含有字母’x’,可以位于开头,结尾或者字符串中间。如果使用NOT关键字则可达到相反的效果。 |
| A RLIKE B, A REGEXP B | STRING 类型 | B是基于java的正则表达式,如果A与其匹配,则返回TRUE;反之返回FALSE。匹配使用的是JDK中的正则表达式接口实现的,因为正则也依据其中的规则。例如,正则表达式必须和整个字符串A相匹配,而不是只需与其字符串匹配。 |
4.4.7 like 和 rlike
1) like
% : 代表零个或者是多个字符(即时任意字符)
_ : 代表一个字符;
\ : 转义字符;
2) Rlike :后面紧跟随正则表达式
\ : 转义字符,即屏蔽特殊字符的含义:\$;
^ : 从头开始匹配,如:name rlike ^a : 表示以a开头的name
$ : 匹配结尾 ,如 name Rlike t$ :匹配以t结尾的name
* : 0-n 个 ,如 name rlike a* : 匹配 0-n a的name
[] : 表示范围,如 [0-9,a-z]:匹配0-9或者是a-z都可以。4.4.8 逻辑运算符
| 操作符 | 含义 |
|---|---|
| AND | 逻辑并 |
| OR | 逻辑或 |
| NOT | 逻辑否 |
4.5 分组
4.5.1 group by
- 常和聚合函数在一起;
- 出现在 group by 中的字段可以出现在 select中,也可以不出现,
但是出现在 select中字段(除函数和常量外)必须在group by 出现过的字段。4.5.1 Having
having 与 where 的不同
1) where 后面不能写分组函数,但是 having 可以 ;
2) having 只用于 Group by 分组统计语句;4.6 join
-- 说明:
1) 常见的7种 join 要会写;
2) 不支持非等值连接;
3) 支持满外连接 : full join ;
4) 关于主表和从表: -- 左右外连接,主表数据全要,从表数据只要交集的部分。
左外连接 : 左边为主表,右边为从表 ;
右外连接 : 右边为主表,左边为从表。4.7 排序
4.7.1 全局排序 : Order By
1) 全局排序,只能有一个Reducer ;
2) DESC : 降序 ;
3) ASC : 升序('默认值');
4) Order by 子句必须在SELECT语句的结尾 ;
5) 排序的字段可以是多个;
示例:
select id , name ,sal from emp order by sal desc ,name asc ;
-- 先按照薪水降序,薪水相同的,则按照名字进行升序排序;4.7.2 mapreduce内部排序 :sort by
1) 理解:
理解为在 reduce 中进行排序。所以一般是需要有多个 reduce 才有作用,是在每个reduce中进行排序,属于局部排序,而不是全局排序。
2) 使用场景:
当数据量很大时,不要进行全局排序,只需要进行局部排序。
3) 一般不单独使用,因为无法控制什么样的数据进入同一个 reduce 中;
-- 一般配合distribute by 使用,分区排序就是指定什么样的数据会进入同一个reduce中。
4) 单独使用时,进入同一个 reduce 任务中的数据是随机的。 -- 伪随机,就是每次计算的结果是一样的,但是进入每一个reduce 中的数据是随机的。
-- 示例:
1) 设置reducer的个数:
set mapreduce.job.reduces=3; -- 设置reduce个数为3
2) 根据部门编号降序查看员工信息 :
select * from emp sort by deptno desc;
-- 此时生成3个结果文件,并且每个结果文件中均是按照deptno 进行降序排序。4.7.3 分区排序 : distribute by
1. 理解 : 类似在 MapReduce 中的自定义分区(partition );
2. 一般就是配合 sort by 使用;
3. 同样,在使用的时候,不能是一个reduce,需要多个reduce;
4. 什么样的数据会进行同一个reduce 呢 ?
1)首先,这个分区不是很智能,使用的方式是:分区的字段的 ( hashcode % reduce的个数 ),计算值相等的,则进入同一个reduce;
2)不会使用toString方式进行分区。
5. distribute by 必须写在sort by 的前面;
6. tez 引擎会进行reduce的优化,即假设设置为3个reduce,但是运行时有可能是2个reduce,所以验证时032,需使用mr引擎。-- set hive.execution.engine=mr;
-- 示例:
insert overwrite local directory '/opt/module/hive/datas/distribute-result' select * from emp distribute by deptno sort by empno desc; -- 假设 reduce = 3 ;
-- 先按照deptno进行分区(m = hashcode(deptno) % 3 , m值相等的数据进入同一个分区),然后在分区内进行局部排序,最后将查询的结果导出到本地指定的一个文件中。4.7.4 Cluster By
1. 理解 :当distribute by 和 sort by 的字段相同时,可以使用Cluster by 进行替代;
2. 不能指定排序的顺序,只能是升序。
-- 示例:
方式一 :select * from emp cluster by deptno ;
方式二 :select * from emp distribute by deptno sort by deptno ;
-- 方式一和方式二是等价的。五、 分区表和分桶表
5.1 分区表
分区表的解析:
-- 理解:
1) Hive 中的分区就是分目录 ;
2) 分区表对应一个hdfs文件系统的独立的文件;
3) 实际上是把一个大的数据集根据业务的需求分割成多个小的数集;
4) 在查询时,通过where语句进行条件筛选,指定数据在哪个分区内,提高查询的效率;
5) 同时用于解决数据倾斜的问题。5.1.1 分区表的基本操作
- 创建分区表
-- 语法:
create table [if not exists] 表名 (
字段1 数据类型1,
字段2 数据类型2,
字段3 数据类型3,
...
)
partition by (字段1 数据类型1 , 字段2 数据类型2 ,...) -- 分区,字段不能与表中属性字段相同
clustered by (字段1 , 字段2 , ...) -- 分桶,字段来自于表中的字段,所以是没有数据类型的。
row format delimited fields terminated by '\t'
-- 分区的字段也是可以作为表的字段使用。
-- 示例:
create table dept_partition(
deptno int ,
dname string ,
loc string
)
partition by (month string , day string) -- 二级分区,先按照月进行分区,在月中再根据day进行分区
row format delimited fields terminated by '\t'- 加载数据
方式一 : 常规加载数据 load方式
-- 语法:
load data local inpath '本地数据路径' into table 表名 partition by (字段1'***',字段2 '***')
-- 示例:
load data local inpath '/opt/module/hive/datas/2020-04-04.log' into table dept_partition partition by (month='2020-04',day='04')
方式二:上传数据后修复 -- 因为单独上传数据到指定的目录下,hive是不能自动读取,需要进行数据的修复
第一步: 根据分区字段的信息,创建文件夹,此文件夹与表的路径相同
第二步: 本地的数据上传到指定的目录下,使用 【 hdfs dfs -put 本地数据路径 hdfs文件路径 】
第三步: 进行数据的修复 ,使用语句 【msck repair table 表名】
方式三: 上传数据后添加分区的方式 -- 该方式使用的情况最多
第一步和第二步与方式二完全相同;
第三步: 执行添加分区的方式
alter table 表名 add partition (字段1='***',字段2='***')
-- 实例:
第一步:hdfs dfs -mkdir -p /user/hive/warehouse/dept_partition/month=2020-04/day=04 ;
第二步:hdfs dfs -put /opt/module/hive/datas/2020-04-04.logs /user/hive/warehouse/dept_partition/month=2020-04/day=04
第三步:
方式二: msck repair table dept_partition;
方式二: alter table dept_partition add partition (month='2020-04',day='04');- 根据分区进行查询
-- 语法:
查询语句 + where 分区字段='***' ;
-- 示例:
select * from dept_partition where day='04' or day='05' ;- 增加分区
-- 语法:
alter table 表名 add partition (字段1="***",字段2='***') partition (字段1="***",字段2='***');
-- 说明:
增加多个分区时,分区与分区之间使用空格隔开。- 删除分区
-- 语法:
alter table 表名 drop partition (字段1="***",字段2='***') , partition (字段1="***",字段2='***');
-- 说明:
删除的多个分区之间使用','进行分隔。- 查看多个分区
-- 语法:
show partitions 表名;5.1.2 动态分区调整
-- 理解:为什么要使用动态分区呢?
在实际的情况中,我们的数据通过前端收集过来以后,一般都是存储在hdfs上面,我们只需要通过 insert + 查询语句的方式将数据导入到指定的数据表,在此时需要指定按照什么字段进行分区。- 前期的准备工作--开启动态分区参数设置
(1)开启动态分区功能(默认true,开启)
hive.exec.dynamic.partition=true
(2)设置为非严格模式(动态分区的模式,默认strict,表示必须指定至少一个分区为静态分区,nonstrict模式表示允许所有的分区字段都可以使用动态分区。)
hive.exec.dynamic.partition.mode=nonstrict
(3)在所有执行MR的节点上,最大一共可以创建多少个动态分区。默认1000
hive.exec.max.dynamic.partitions=1000
(4)在每个执行MR的节点上,最大可以创建多少个动态分区。该参数需要根据实际的数据来设定。比如:源数据中包含了一年的数据,即day字段有365个值,那么该参数就需要设置成大于365,如果使用默认值100,则会报错。
hive.exec.max.dynamic.partitions.pernode=100
(5)整个MR Job中,最大可以创建多少个HDFS文件。默认100000
hive.exec.max.created.files=100000
(6)当有空分区生成时,是否抛出异常。一般不需要设置。默认false
hive.error.on.empty.partition=false- 实操
-- 需求:将dept表中的数据按照地区(loc字段),插入到目标表dept——partition的分区中:
1)创建目标dept_partition表
create table dept_partition (
id int,
name string
)
partitioned by (loc string)
row format delimited fields terminated by '\t';
2) 插入数据
insert into table dept_partition partition (loc) select deptno , name, loc from dept;5.2 分桶表
-- 理解:为什么会有分桶表?或者说分桶表是用来解决什么问题呢?
1)提供一个数据隔离和优化查询的便利方式,如当某一个表或者是某一个分区的数据量特别大时,通过分桶的方式,可以将数据再进行分解成多个模块,这样在进行查询时,提供了查询的效率。 -- 说明查询的分区操作时自动的。
2)什么样的数据会进入同一个桶中呢?
通过 (分桶字段的)hashcode % 桶的个数 ,取模数相等的进入同一个桶内。(不适用于TEZ引擎)
3)分桶表针对的是数据文件;而分区是针对数据路径。创建分桶表
在创建表单时,增加如下语法子句:
******
clustered by (字段1,字段2,***) into num buckets;
******
-- 说明:
1) 字段1-n : 均来自于表中的字段;
2) num : 表示分桶的个数。5.3 抽样查询
-- 理解:
当数据特别大的时候,我们不要通过查询所有的数据来获取数据的情况。
例如:工厂生产的产品,OQC 是按比例抽样来判定产品的良率。
-- 示例:
select * from dept tablesample (bucket 1 out of 4 on id);
-- 说明:
on :表示依据哪个字段进行抽样;
4 : 表示按照on后面的字段将数据分成几份。
1 : 则表示第一份,2 表示第二份。
如上只是抽样方法中非常简单的一种,还有很多种方式。六 、函数 (重点)
6.1 常用函数
日期函数:
1) unix_timestamp : 返回当前或指定的时间戳;
SELECT unix_timestamp("2020-05-02 11:22:00"); ==>1588418520
2) from_unixtime : 将时间戳转化为日期格式
SELECT FROM_unixtime(1588418520); ==> 2020-05-02 11:22:00
3) current_date : 当前日期
4)current_timestamp: 当前日期 + 时间;
5)to_date : 获取日期部分
6)year/month/day/hour/minute/second() : 获取年、月、日、小时、分、秒
7)weekofyear(): 当前时间是一年中的第几周
8)dayofmonth(): 当前时间是一个月中的第几天
9)months_between() : 两个日期间的月份
10) datediff() : 两个日期相差的天数
11) add_months:日期加减月
12) date_add:日期加天数
13) date_sub:日期减天数
14) last_day: 日期的当月的最后一天取整函数
1) round: 四舍五入
2) ceil: 向上取整
3) floor: 向下取整字符串函数
1)upper: 转大写
2)lower: 转小写
3)length: 长度
4)trim: 前后去空格
5)lpad: 向左补齐,到指定长度
6)rpad: 向右补齐,到指定长度
7)regexp_replace: SELECT regexp_replace('100-200', '(\\d+)', 'num') ;
使用正则表达式匹配目标字符串,匹配成功后替换!集合操作
1) size: 集合中元素的个数
2) map_keys: 返回map中的key
3) map_values: 返回map中的value
4) array_contains: 判断array中是否包含某个元素
5) sort_array: 将array中的元素排序6.2 系统内置函数
1) 查看系统自带的函数
show functions;
2) 查询函数的用法
desc function extended 函数名6.3 常用的内置函数
6.3.1 空字段赋值 NVL
-- 语法:
nvl(value,default_value)
-- 说明:
1)如果value 为null,则返回default_value ,否则返回vaule;
2)如果两个值(value , default_value)均为null,则返回null;6.3.2 CASE WHEN
-- 示例:
select
dept_id,
sum(case sex when '男' then 1 else 0 end) male_count,
sum(case sex when '女' then 1 else 0 end) female_count
from
emp_sex
group by
dept_id;
/* 解读:
1.按照dept_id 进行分组,同一组的数据先进行计算;
2.假设dept_id=10的数据有10条,则10数据分别在sum函数中进行计算,计算完成以后得出一个结果;
3.一组数据最后得到一条数据结果。
*/6.3.3 行转列
-- 相关函数
1) concat('str1','str2','str3',...) : 表示将str1/str2/str3... 依次进行连接,str1/str2/str3... 可以说任何数据类型;
-- 示例:SELECT concat('132','-','456'); ==> 132-456
2) concat_ws('连接符','str1','str2',...) : 表示使用'连接符'将str1/str2...依次进行连接,str1/str2...只能是字符串或者是字符串数组。
-- 示例:
SELECT concat_ws('-','java','maven'); ==> java-maven;
SELECT concat_ws(null,'java','maven'); ==> null -- 当连接符为null时,结果返回null
SELECT concat_ws('.', 'www', array('facebook', 'com')) ;==> www.facebook.com
3) collect_set(col) : 函数只接受基本数据类型,它的主要作用是将某字段的值进行去重汇总,产生array类型字段
-- 示例:
SELECT COLLECT_set(deptno) from emp; ==>[20,30,10]6.3.4 列转行
-- 语法:
lateral view explode (split(字段,分割符)) 表名 as 列名
-- 说明:
lateral view : 侧写;
explode(): 将指定的集合拆解分成多行 -- 炸裂
split(字段,分割符) : 将指定的字符串按照分割符封装成一个集合。
-- 示例:
SELECT movie,category_name
FROM movie_info
lateral VIEW
explode(split(category,",")) movie_info_tmp AS category_name ; -- categor_name 为炸裂的列名,move_info_tmp为侧写的表名

6.4 开窗函数
相关函数说明:开窗函数是为每一条数据进行开窗
1) over() : 单独使用此函数,默认的窗口大小为结果集的大小。
2) partition by : 在窗口函数中进行分区
over(partition by 字段) :对结果集内进行分区,每条数据的开窗大小为该结果集中分区集的大小。
3) over( order by 字段) : 在窗口函数中只用到了order by 排序时,也会对每条数据进行开一个窗口,默认的开窗大小为:从结果集的开始位置到当前处理数据的位置。
-- 实例:
-- 1.查询在2017年4月份购买过的顾客及总人数
-- 解析,顾客全部要,多个顾客,多行,人数为一个值,一行,则是需要进行开窗,因为不是一一匹配的。
SELECT name ,
COUNT(*) OVER () `人数`
from business
WHERE SUBSTRING(orderdate,1,7)='2017-04'
group by name ;
-- 2.查询顾客的购买明细及月购买总额
SELECT name ,orderdate ,cost ,
sum (cost) over(partition by MONTH (orderdate))
from business;
-- 3.上述的场景, 将每个顾客的cost按照日期进行累加
SELECT name ,orderdate ,cost ,
sum (cost) over(partition by name order by orderdate)
from business;
4) CURRENT ROW:当前行
n PRECEDING:往前n行数据
n FOLLOWING:往后n行数据
5)UNBOUNDED:起点,
UNBOUNDED PRECEDING 表示从前面的起点
UNBOUNDED FOLLOWING 表示到后面的终点
6)LAG(col,n,default_val):往前第n行数据
7)LEAD(col,n, default_val):往后第n行数据
8)NTILE(n):把有序窗口的行分发到指定数据的组中,各个组有编号,编号从1开始,对于每一行,NTILE返回此行所属的组的编号。注意:n必须为int类型。
示例:
-- 需求:查询前20%时间的订单信息
select * from (
select name,orderdate,cost, ntile(5) over(order by orderdate) sorted
from business
) t
where sorted = 1;6.5 Rank
-- 函数说明
1) RANK() 排序相同时会重复,总数不会变;
-- 1 2 2 4 5 5 7
2) DENSE_RANK() 排序相同时会重复,总数会减少;
-- 1 2 2 3 3 4 4 5
3) ROW_NUMBER() 会根据顺序计算。
-- 1 2 3 4 5 66.6 自定义函数
自定函数的分类:
1) UDF(User-Defined-Function) -- 一进一出
2) UDAF(User-Defined Aggregation Function) -- 聚集函数,多进一出
类似于:count/max/min
3) UDTF(User-Defined Table-Generating Functions) -- 一进多出
如lateral view explode()6.6.1 自定义UDF函数
- 需求:UDF实现计算给定字符串的长度
示例:
select my_len("abcd"); ==> 4- 创建一个Maven工程
- 导入依赖
<dependencies>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>3.1.2</version>
</dependency>
</dependencies>- 创建一个类继承于GenericUDF
package com.lianzp.hive;
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.exec.UDFArgumentLengthException;
import org.apache.hadoop.hive.ql.exec.UDFArgumentTypeException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDF;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
/**
* 自定义UDF函数,需要继承GenericUDF类
* 需求: 计算指定字符串的长度
*/
public class MyStringLength extends GenericUDF {
/**
*
* @param arguments 输入参数类型的鉴别器对象
* @return 返回值类型的鉴别器对象
* @throws UDFArgumentException
*/
@Override
public ObjectInspector initialize(ObjectInspector[] arguments) throws UDFArgumentException {
// 判断输入参数的个数
if(arguments.length !=1){
throw new UDFArgumentLengthException("Input Args Length Error!!!");
}
// 判断输入参数的类型
if(!arguments[0].getCategory().equals(ObjectInspector.Category.PRIMITIVE)){
throw new UDFArgumentTypeException(0,"Input Args Type Error!!!");
}
//函数本身返回值为int,需要返回int类型的鉴别器对象
return PrimitiveObjectInspectorFactory.javaIntObjectInspector;
}
/**
* 函数的逻辑处理
* @param arguments 输入的参数
* @return 返回值
* @throws HiveException
*/
@Override
public Object evaluate(DeferredObject[] arguments) throws HiveException {
if(arguments[0].get() == null){
return 0 ;
}
return arguments[0].get().toString().length();
}
@Override
public String getDisplayString(String[] children) {
return "";
}
}- 打成jar包上传到服务器/opt/module/hive/datas/myudf.jar
- 将jar包添加到hive的classpath
add jar /opt/module/hive/datas/myudf.jar;- 创建临时函数与开发好的java class关联
create temporary function my_len as "com.lianzp.hive. MyStringLength";- 即可在hql中使用自定义的函数my_len
select ename,my_len(ename) ename_len from emp;6.6.2 自定义UDTF函数
和udf的最大区别就是自定义函数不同。
package com.lianzp.udtf;
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDTF;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspectorFactory;
import org.apache.hadoop.hive.serde2.objectinspector.StructObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
import java.util.ArrayList;
import java.util.List;
public class MyUDTF extends GenericUDTF {
private ArrayList<String> outList = new ArrayList<>();
@Override
public StructObjectInspector initialize(StructObjectInspector argOIs) throws UDFArgumentException {
//1.定义输出数据的列名和类型
List<String> fieldNames = new ArrayList<>();
List<ObjectInspector> fieldOIs = new ArrayList<>();
//2.添加输出数据的列名和类型
fieldNames.add("lineToWord");
fieldOIs.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);
return ObjectInspectorFactory.getStandardStructObjectInspector(fieldNames, fieldOIs);
}
@Override
public void process(Object[] args) throws HiveException {
//1.获取原始数据
String arg = args[0].toString();
//2.获取数据传入的第二个参数,此处为分隔符
String splitKey = args[1].toString();
//3.将原始数据按照传入的分隔符进行切分
String[] fields = arg.split(splitKey);
//4.遍历切分后的结果,并写出
for (String field : fields) {
//集合为复用的,首先清空集合
outList.clear();
//将每一个单词添加至集合
outList.add(field);
//将集合内容写出
forward(outList);
}
}
@Override
public void close() throws HiveException {
}
}七 、 压缩与存储
总结几点:
1)不同存储格式的存储文件的大小对比总结:
ORC > Parquet > textFile
2)存储文件的查询速度测试:基本相差不大。
-- 在实际的项目开发当中,hive表的数据存储格式一般选择:orc或parquet;压缩方式一般选择snappy,lzo。压缩方式:
| 压缩格式 | 工具 | 算法 | 文件扩展名 | 是否可切分 |
|---|---|---|---|---|
| DEFLATE | 无 | DEFLATE | .deflate | 否 |
| Gzip | gzip | DEFLATE | .gz | 否 |
| bzip2 | bzip2 | bzip2 | .bz2 | 是 |
| LZO | lzop | LZO | .lzo | 是 |
| Snappy | 无 | Snappy | .snappy | 否 |
编码/解码器:
| 压缩格式 | 对应的编码/解码器 |
|---|---|
| DEFLATE | org.apache.hadoop.io.compress.DefaultCodec |
| gzip | org.apache.hadoop.io.compress.GzipCodec |
| bzip2 | org.apache.hadoop.io.compress.BZip2Codec |
| LZO | com.hadoop.compression.lzo.LzopCodec |
| Snappy | org.apache.hadoop.io.compress.SnappyCodec |
压缩性能的比较:
| 压缩算法 | 原始文件大小 | 压缩文件大小 | 压缩速度 | 解压速度 |
|---|---|---|---|---|
| gzip | 8.3GB | 1.8GB | 17.5MB/s | 58MB/s |
| bzip2 | 8.3GB | 1.1GB | 2.4MB/s | 9.5MB/s |
| LZO | 8.3GB | 2.9GB | 49.3MB/s | 74.6MB/s |
create table log_parquet_snappy(
track_time string,
url string,
session_id string,
referer string,
ip string,
end_user_id string,
city_id string
)
row format delimited fields terminated by '\t'
stored as parquet -- 指明文件的存储格式
tblproperties("parquet.compression"="SNAPPY"); -- 指明文件的压缩方式详情见老师文档。
八 、企业级优化
见老师文档





