Scala 总结(上篇)
Scala 总结(上篇)
一、java知识点重新认识
1.1 静态代码块
-- 问题:静态代码块一定会执行吗?
-- 回答:不一定,那如何理解呢?
之前的理解是:当一个类被加载以后,则这个类中静态代码块一定会执行,则是如何理解类被加载这件事情呢?
通过如下的例子发现,加了final属性的类,通过反编译发现,该属性的赋值操作不是在静态代码中执行,导致静态代码块没有被加载。
--原因是:
调用代码1加载过程:加载age属性-->加载静态代码块-->在静态代码块中执行赋值age=20操作
调用代码2加载过程:加载age属性-->赋值age=20
导致上述的结果是,在主代码中只使用到了age属性,其他均未被使用,所以没有被执行到。
--发现:即使在类中没有静态代码块时,依然会有一个静态代码块。//主代码
public class Test01_StaticBlock {
public static void main(String[] args) {
System.out.println(Emp01.age);
System.out.println(Emp02.age);
}
}// 调用的代码1:
public class Emp01 {
public static int age = 20;
static {
System.out.println("emp01....");
}
}// 调用的代码2:
public class Emp02 {
public final static int age = 20; // 在验证代码1的基础上增加了final关键字
static {
System.out.println("emp02....");
}
}1.2 String类型的不可变性
-- 问题:字符串的不可变性是指什么不可变?
-- 答案:
是指字符串变量的地址不可变,但是字符串的值是可变的,如何验证呢?
使用反射的方式可以验证,见如下代码:
-- 注意事项:
进行数据清洗的时候要注意:
欧美是半角空格;
亚洲和非洲是全角空格。public class String_Change {
public static void main(String[] args) throws NoSuchFieldException, IllegalAccessException {
String s = " 2 3 " ;
String s1 = s ; //将改变内容前的地址赋值给s1
System.out.println("改变s的内容前,s1的内容" + s1);
Class<? extends String> sClass = s.getClass();
//获取属性
Field value = sClass.getDeclaredField("value");
//获取属性值
value.setAccessible(true);
char [] v = (char [] )value.get(s);
v[2] = 'b';
System.out.println("!" + s + "!"); // ! 2b3 ! ,说明值发生了改变
System.out.println("改变s的内容后,s1的内容" + s1);
//判断改变前后,字符串变量指向的地址值是否有变化
System.out.println(s == s1); //true,说明地址没有变化
}
}1.3 关于 ++ 、- - 的区别
//例题1:
int m = 10 ;
int n = m++;
System.out.println("n=" + n); // n=10
System.out.println("m=" + n); // m=11
//例题2:
int m = 10 ;
m = m++;
System.out.println("m=" + m); // m=10
/*
问题:为什么两种情况下,m 的值会不一样呢?如何理解这个问题
剖析:
1.=,赋值,指将右边运算结果给到左边
例题1: int n = m++;
等价于两步骤:
步骤一:计算右边的结果:a = m++
a = m++ --》 a = m = 10, m = m + 1 =11 --》a = 10, m = 11
步骤二:将右边的计算结果赋值给左边:n = a = 10
所以,最终 n = 10 , m = 11
例题2:m = m++;
等价于两步骤:
步骤一:计算右边的结果:a = m++
a=m++ --》 a = m = 10, m = m + 1 = 11 --》a = 10 , m = 11
步骤二:将右边的计算结果赋值给左边:m = a = 10
所以m=11 --》 m=10
所以,最终m=101.4 hashmap红黑二叉树问题
-- 问题 : 在极限的情况下,Hashmap放置多少个数据就会将链表转换成红黑二叉树呢?
-- 回答 :
之前理解是:当集合数组长度大于64且单个数组位置的数据超过8时,该位置的数据将从链表结构转换成红黑二叉树的结构。
但是:在极限情况下(当所有的数据只向数组中一个位置添加数据),某一个位置满足11条数据时,就会转换成红黑二叉树结构。
-- 如何理解上面结果呢?
-- 验证方式:通过debug的方式查看实际的过程。
-- 具体的过程如下:
1.前提,向hashmap中添加数据,且让数据只向集合数组中的同一个位置进行添加。
如何保证能够数据只向数组中同一个索引位置添加数据呢?
a、对key进行hashcode,然后再和(length-1)进行 & 运算,结果相同的数据进入数组中同一位置;
b、首先比较新增数据和原数组中数据的hashcode是否相等,如果不相等,则直接添加成功,如果hashcode相等,则通过调用key中equals()方法比较新增数据和原数组位置的链表数据是否相等,不等则添加成功,相等则替换;
则我们只要保证每个数据key的hashcode相同,equals()方法的返回值保持不同即可。
2.具体过程
a、当hashmap某一个位置,链表数据的个数超过8个(即当有9个时),会尝试转换为二叉树;
b、转换前,首先判断数组容量是否足够大,如果不够大,则进行扩容,发现16长度小,则扩容为原来的2倍,数组的长度16*2=32;
c、添加第10个数据时,同样尝试转换为二叉树,转换前,发现32长度还较少,则继续扩容,此时数组的长度为32*2=64;
d、添加第11个数据时,同样尝试转换为二叉树,转换前,发现64长度已经不少了,则将链表转换为二叉树。
3.问题:在形成二叉树前为什么要进行扩容呢?
通过扩容的方式,提升数据进入数组中其他位置的可能性,尽量让数据平均分布在数组的各个位置。1.5 hashmap扩容为什么必须是2倍
-- 原因
和hashmap确认数据在数组中哪个位置的算法有关系。
计算方式:(key)hashcode & (length - 1 )
1.底层默认的数组长度是16,2倍扩容策略,确保了length -1 的二进制数值从第一个1到最后一位均是1
如:
16-1=15 --> 0000 1111
32-1=31 --> 0001 1111
64-1=63 --> 0011 1111
128-1=128 --> 0111 1111
2.这样一来,任何二进制数 & length-1 的计算结果,一定是在 [0,length-1]区间,且[0,length-1]区间任意一个数均是可以取到的,确保数组每个位置均可以存储到数据。二、Scala基础知识
2.1 关于 类名.class 和 类名$.class文件
- 第一步:scala代码【没有main方法】
创建两个字节码文件:Test
$.class 和 Test.classTest.class : 普通不可变的类
Test
$.class: ① 静态代码块(加载此类时会创建此类的对象) ② 静态属性,类型为当前类
③ 将获取的对象赋值给静态属性
object Test {
}Test.class代码内容
package com.atguigu;
import scala.reflect.ScalaSignature;
public final class Test {}Test$.class 代码内容:
package com.atguigu;
public final class Test`$`{
public static Test`$` MODULE`$`; //一个静态属性
static {} //创建了当前类的一个对象 ,0: new #2 // class com/atguigu/Test`$`
private Test`$`() { MODULE`$` = this; } //私有的空参构造器,this
}使用反编译:Javap -c -l 类名可以查询
D:\01_workspace\workspace_idea\atguiguJavaEE\test_0213\Scala\target\classes\com\atguigu>javap -c -l Test`$`
警告: 二进制文件Test`$`包含com.atguigu.Test`$`
Compiled from "Test.scala"
public final class com.atguigu.Test`$` {
public static com.atguigu.Test`$` MODULE`$`;
public static {};
Code:
0: new #2 // class com/atguigu/Test`$`
3: invokespecial #12 // Method "<init>":()V
6: return
}- 第二步:scala代码加入main方法
- Test.class : 创建了静态的main(),调用Test
$.class的静态属性,返回值是Test$.class类的对象,通过对象调用Test$.class类中的普通main方法; - Test
$.class :创建了一个无方法体的普通main方法
- Test.class : 创建了静态的main(),调用Test
object Test {
def main(args : Array[String]) : Unit = {
}
}Test.class代码内容
package com.atguigu;
import scala.reflect.ScalaSignature;
public final class Test {
public static void main(String[] paramArrayOfString) {
// 调用Test`$`.class的静态属性,返回值是Test`$`.class的对象,通过对象调用Test`$`.class类中的普通main方法
Test`$`.MODULE`$`.main(paramArrayOfString);
}
}Test$.class代码内容
package com.atguigu;
public final class Test`$`{
public static Test`$` MODULE`$`; //静态属性
static {
}
public void main(String[] args) {} //创建了一个普通的main方法
private Test`$`() { MODULE`$` = this; } //给静态属性赋值,值为当前类的一个实例对象
}- 第三步:在scala代码中加入println()方法
- Test.class: 没有变化,依然是通过调用Test
$.class对象.main() - Test
$.class :在普通main()体内增加了scala方法体内的代码
object Test {
def main(args : Array[String]) : Unit = {
println("test");
}
}Test$.class 代码内容
package com.atguigu;
import scala.Predef`$`;
public final class Test`$` {
public static Test`$` MODULE`$`;
static {
}
// 在mian方法中加入了println()代码
public void main(String[] args) { Predef`$`.MODULE`$`.println("test"); }
private Test`$`() { MODULE`$` = this; }
}- 总结
-- 第一步:scala代码【没有main方法】
创建两个字节码文件:Test`$`.class 和 Test.class
1.Test.class : 普通不可变的类
2.Test`$`.class : ① 静态代码块(加载此类时会创建此类的对象)
② 静态属性,类型为当前类'Test`$`'
③ 将获取的对象实例赋值给静态属性
-- 第二步:scala代码加入main方法
1.Test.class : 创建了静态的main,调用Test`$`.class的静态属性,返回值是'类名`$`'的对象,通过对象调用Test`$`.class类中的main()方法;
2.Test`$`.class :创建了一个无方法体的main()方法
-- 第三步: 在scala代码中加入println()方法
1.Test.class : 没有变化,依然是通过调用Test`$`.class对象.main()
2.Test`$`.class : 在main()体内增加了scala方法体内的代码
-- 总结
如果没有将scala源代码声明成object(模拟java中的静态语法),就不会生产 Test`$`.class文件,则不会创建 Test`$`类的对象,同时在scala逻辑代码也不会在体现,则此时的scala是无法执行。2.2 代码解析
- 代码
object Scala01_Hello {
// public static void main(String[] args)
def main(args: Array[String]): Unit = {
// 方法体
System.out.println("Hello Scala")
// 打印
println("Hello Scala")
}
}- 解析
-- 1.object
1. scala语言没有静态的语法,采用object方法模仿java的静态方法,通过类名对象.方法
2. scala是一个完全面对对象编程语言;
3. java不是一个完全面向对象编程语言。
-- 2.def
define的缩写,声明方法或函数的关键字
-- 3.agrs : Array[string] :参数说明
1. scala : 变量名 : 数据类型
java : 数据类型 变量
2. Array : scala的数组,相当于java中的 []
3. [String] : 泛型
-- 4.unit
Unit(类型) <==> void(关键字)
*
-- 5. = : 赋值,方法也是对象,可以赋值
*
* Scala语言是基于java语言开发的。所以可以直接嵌入java代码执行
*
* Scala语言中默认会导入一些对象,那么这些对象的方法可以直接使用
* 类似于java中import java.lang2.3 方法解析
object Scala02_Test {
// 声明方法 def
// 名称(参数列表) : 类型
// 参数名: 参数类型
// 方法赋值
def main( args : Array[String] ) : Unit = {
// 方法体
println("Hello Test")
// 调用方法
println(Scala02_Test.test())
}
def test() : String = {
return "test"
}
}2.4 scala的calss类
// 使用class关键字声明的类,在编译时,只会产生一个类文件,并且不能模仿静态语法操作
class Scala03_Class {
def main(args: Array[String]): Unit = {
}
}三、变量和数据类型
3.1 变量
-- 1.声明语法
var/val 变量名称 : 变量类型 = 变量值
-- 2.特点
1.如果可以通过语法推断出来变量类型,那么变量在声明时可以省略类型;
2.Scala是静态类型语言,在编译时必须要确定变量类型;
3.变量必须显示的初始化,不能省略;
4.var和val变量类型一旦确定以后就不能变化;
5.var声明的变量的值"可以"改变,val声明的变量的值"不可以"改变
6.val比var使用的场景更多,更广
-- 3.例子:
var name : String
= "zhangsan"
var name = "zhangsan" -->类型推断
name = "lisi" -->可变变量
val age = 10 --> 类型推断
age = 20 --> 报错,不可变变量,不能改变值
val id : Int -->报错,变量必须显式化赋值
id = 10
-- 4.说明:
整型对象默认类型:Int
浮点型对象默认类型:Double
-- 5.val 和 常量的区别:
"123"、"张三"、2 --> 常量
val name = "zhangsan" -->name是不可变变量,首先它是一个变量3.2 标识符
-- 标识符规则 ,就是起名字,如给变量、类、方法、函数起名
1.Scala标识符分为字符+数字、字符两种
2.命名的规则如下:
a.不能以数字开头
b.不能使用关键字和保留字
c.不限制长度
d.区分大小写
e.有很多符号也可以作为标识符
-- 如何使用标识符
1.随便起,报错就换一个
2.常见用于语法操作的符号不能用:
{}、“”、‘’、() ,:,[]
3.`$`,这个符号能不用就尽量不用
4.如果就是要使用关键字作为名字,使用"飘号"处理。
如:`private`举例:
object Scala_Identifier {
def main(args: Array[String]): Unit = {
//调用此方法
println(:>()) //lianpeng ()
}
//定义一个方法,方法名是 :> ,返回值类型是Unit,返回值是:()
def :>(): Unit = {
println("lianpeng")
}
}3.3 Scala与Java的互访问方式
//Scala访问java,直接访问,因为Scala是基于java开发
object Scala_java {
def main(args: Array[String]): Unit = {
val user = new User
println(user.age)
}
def test () : Unit={
println("你好啊")
}
}// java访问Scala
public class test {
public static void main(String[] args) {
Scala_java.test(); //因为Scala中的类名就是一个对象,导入包以后直接使用就可以
}
}3.4 字符串
在 Scala 中,字符串的类型实际上就是 Java中的 String类,它本身是没有 String 类的。
在 Scala 中,String 是一个不可变的字符串对象,所以该对象不可被修改。这就意味着你如果修改字符串就会产生一个新的字符串对象
object Scala_String {
def main(args:Array[String]):Unit={
val str = "lianzhipeng"
val str1 = str.substring(0,2) //取第一个和第二个字母
println(str) // lianzhipeng
println(str1) // li
}
}3.4.1 字符串连接
object Scala_String {
def main(args:Array[String]):Unit={
val s = "java"
println(s + " bigdata") //使用 + 号
}
}3.4.2 传值字符串
格式:
//语法如下:注意使用的是 printf (使用的情况较少)
printf("name=%s,years=%s",s,yesrs)object Scala_String {
def main(args:Array[String]):Unit={
val s = "java"
val yesrs = 12
//语法如下:注意使用的是 printf
printf("name=%s,years=%s",s,yesrs) //name=java,years=12
}
}3.4.3 插值字符串
格式:
println(s"name=`$`s,years=`$`yesrs")
//可以在{}内进行相应的操作,`$`{},取{}内的结果
println(s"name=`$`{s.subString(0,1)},years=`$`{yesrs}")object Scala_String {
def main(args : Array [String] ): Unit={
val s = "java"
val yesrs = 12
println(s"name=`$`s,years=`$`{yesr-1}") //name=java,years=11
}
}3.4.4 多值字符串
格式:多行字符串 """ .....""",在封装JSON或SQL时比较常用
// | 表示定格符,s是配合`$`一起使用
val str =
s"""
|`$`s
|`$`yesrs
""".stripMarginobject Scala_String {
def main(args:Array[String]):Unit={
val s = "java"
val yesrs = 12
// 使用三个分号表示:多行字符串 """ ....."""
// | 表示定格符,s是配合`$`一起使用
// 在封装JSON或SQL时比较常用
val str =
s"""
|`$`s
|`$`yesrs
""".stripMargin
println(str) //
}
}3.5 输入输出
3.5.1 从控制台输入
-- 方法:
使用StdIn对象,调用内部的方法,可以有很多种方式,如:
.readInt() : 读取一个数字转换为Int类型
.readLine() : 读取一行内容转换为String类型
......object Scala_Input {
def main(args: Array[String]): Unit = {
//从控制台获取输入转换为String类型
val i = StdIn.readLine()
println(i)
}
}3.5.2 从文本文件中输入
-- 方法:
使用Source.fromFile(文件路径).getlines()
--说明:
文件路径:从相对路径中读取文件数据, IDEA中的相对路径,是以Project的根(root)路径为基准object Scala_Input {
def main(args: Array[String]): Unit = {
// 返回一个迭代器类型的变量
val strings: Iterator[String] = Source.fromFile("input/test").getLines()
//遍历迭代器
while (strings.hasNext) {
println(strings.next())
}
}3.5.3 输出
object Scala_Input {
def main(args: Array[String]): Unit = {
// 输出的文件必须不存在,但是目录要存在
val out = new PrintWriter(
new FileWriter("output/test.txt")
)
out.write("java")
out.flush()
out.close()
}
}3.5.4 网络(重点)
- 客户端
package com.atguigu.Scala_chapter01.scala_chapter01
import java.io.{OutputStreamWriter, PrintWriter}
import java.net.Socket
/**
* @Description
* *
* @author lianzhipeng
* @create 2020-05-19 22:06:13
*/
object Scala_Client {
def main(args: Array[String]): Unit = {
//获取一个本机的客户端
val client = new Socket("localhost", 9999)
//获取一个输出流
val out = new PrintWriter(
new OutputStreamWriter(
client.getOutputStream,
"UTF-8"
)
)
out.write("scala ,java ")
out.flush()
out.close()
client.close()
}
}- 服务器端
package com.atguigu.Scala_chapter01.scala_chapter01
import java.io.{BufferedReader, InputStreamReader}
import java.net.ServerSocket
/**
* @Description
* *
* @author lianzhipeng
* @create 2020-05-19 22:05:59
*/
object Scala_Server {
def main(args: Array[String]): Unit = {
//创建一个服务器,并指定端口号
val server = new ServerSocket(9999)
//获取客户端
val socket = server.accept()
//获取一个输入流
val reader = new BufferedReader(
new InputStreamReader(
socket.getInputStream,
"UTF-8"
)
)
//读取
val unit = reader.readLine()
println(unit)
}
}3.6 数据类型(重点)
--java 的数据类型
-- 基本数据类型:
byte / short / int / long / float / double / char / boolean
-- 引用数据类型:
集合、数组 、字符串、包装类--Scala 的数据类型
Scala是一个完全面向对象的语言,所以是没有基本数据类型的,那么它的类型有什么呢?
1.值任意对象类型 :AnyVal(value) -->对应了java中的基本数据类型,但是还有一些其他的类型
2.引用任意对象类型 :AnyRef (reference) -->包含了java的数据类型和scala自身的一些类型.png)

上面的图是非常关键的,必须记住。
- 上图的基本说明:
-- AnyVal:
Byte / Short / Int / Long / Double / Float / Double / Char / Boolean / Unit / StringOps
-- AnyRef:
Scala collections / Other Scala classes / all java calsses
-- Implicit Conversion :隐性转换,自动转换
-- Subtype : 子类型
-- AnyVal 和 AnyRef 从图片上看,是没有子类和隐性转换的线连接起来,说明AntVal 和AnyRef两者不可以互相转换;
-- AnyVal 和 AnyRef 两者有一个共同的父类型:Any3.6.1 几个数据类型剖析
3.6.1.1 Unit
1.Unit是Scala的一个类型,"隶属于AnyVal的一个子类类型",它只有唯一值 "()"
2.相当于java中void,"一般使用在方法声明的地方,表示方法没有返回值"
如:
Val u : Unit = ()
println(u) -->结果为 ()
val u : Unit = 1
println(u) -->结果依然是 ()3.6.1.2 Null
1.Null是一个类型,属于 'Scala collections / Other Scala classes / all java calsses '共同的一个子类类型
2.从第一点就可以知道,它是不能被AnyVal使用的。
3.使用时作为一个特殊对象来处理。
如:
Val s = null -->此时s的类型为Null类型
val s1 : String = null -->此时为String类型
val s2 : Int = null --> 运行时报错:Error:type mismatch,found : Null(null) required: Int3.6.1.3 Nothing
1. 没有特殊含义,没有返回值,一般使用在"抛异常"的情况。
2. 属于scala最低层的数据类型,属于任意类型的子类型
3. 纯碎是为了满足scala是一个完全面向对象而设计的//例题1
val s : List[Nothing] = Nil //表示集合中没有任何东西 Nil表示空集合
//例题2
def nothing_test () : Nothing={
throw Exception
}3.6.1.4 Any
1.表示任意类型
2.Any与java中的Object对比
-- Object : 代表引用类型的父类,但是基本类型与Object无关
-- Scala : 是AnyVal(值任意对象类型) 和 AnyRef(引用任意对象类型)
3.此Any类型也是使用比较多,当不知道对象类型时使用。3.6.2 类型转换
3.6.2.1 隐式转换
哪些是可以进行隐式转换的呢?
Byte --> Short (Char) -- > Int --> Long --> Float --> Double
如上对象类型,两两之间是没有任何关系的,但是Scala通过隐式转换规则将Byte转换为Int类型。
也是可以跨级隐式转换的,比如 Byte --> Intobject Scala_DataType {
def main (args : Array[String]) : Unit = {
val b : Byte = 10
val s : Short = b // Byte 隐式转换为 Short 类型
val i : Int = s // Short 隐式转换为 Int 类型
val i1 : Int = b // Byte 隐式转化为 Int 类型
println(i)
}
}3.6.2.2 讨论一下Char
//例题1
val c : Char = 'A' + 1 //编译出错,但是运行成功
println(c) //B
//例题2
val c : Char = 'A'
//编译错误,运行错误,Error:type mismatch; found : Int , required: Char
val c1 : Char = c + 1
println(c)
/*
剖析:出现这种情况原因是什么呢?
这就和常量和不可变量有关系了。
例题1: 'A' + 1 ,是一个常量,在编译的过程中就已经执行了,通过反编码,我们并看不到 'A' + 1 这个操作,所以不会出错。
例题2: 因为c是变量,所以在编译的过程,并不会进行计算,在执行的过程中,发现c + 1是66,一个Int类型,而定义的变量是Char,所以报类型不匹配。
=============================================================================================
同样:在java中这种操作时也是不可行的。
char s = 'A';
char s2 = s + 1 ;
System.out.println(s2); --> Error:java: 不兼容的类型: 从int转换到char可能会有损失3.6.2.3 强制类型转换
-- 什么时强制类型转换?
将精度大的类型转换为精度小的类型,称为强制类型转换
-- 如何实现强制类型转换呢?
1.在java中,采取截取的方式,在结果前面加上强转符
2.在Scala中,采取方法转换的方式。如:对象.toByte
3.Scala的值对象类型之间都提供了相应转换的方法。
-- 例题1
val i: Int = 12
val b = i.toByte
println(b) --> 结果为 : 12
-- 例题2
val i: Int = 66
val b = i.toChar
println(b) -->结果为:B
-- 例题3
val i: Int = 129
val b = i.toByte
println(b) -->结果为:-1273.7 字符串类型转换
1. 所有的对象类型都提供了toString()方法
2. 任意类型都提供了和字符串进行拼接的方法四、运算符
scala运算符的使用和Java运算符的使用基本相同,只有个别细节上不同。
4.1 算术运算符
假定变量 A 为 10,B 为 20

4.2 关系运算符
假定变量A为10,B为20

- scala中的 == 、 equals 、 eq 的区别
val a = new String("abc" )
val b = new String("abc")
println(a==b) // 情况1 true
println(a.equals(b)) // 情况2 true
println(a eq(b)) // 情况3 false
/*
为什么会出现上面的情况呢
1. java中
== : 如果是引用数据类型,比较两者的地址值
如果是基本数据类型,比较两者的数据值
euqals : 只适用于引用数据类型,
未重写equals()方法时,比较的是地址值;
重写equals()方法时,比较实体内容是否相等。
String、包装类、File、Date类中已经重写了equals()方法
===============================================================================
2.scala中
a、== 和 equals
相同点:均是比较两者的实体内容是否相等
不同点:==会对对象进行非空判断,而equals不会
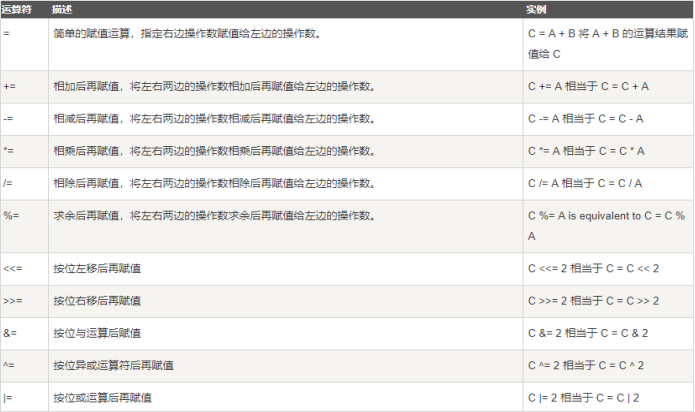
b、eq 用于比较两者的地址值是否相等。4.3 赋值运算符
-- 问题:为什么scala中没有 ++ 和 - - 呢?
-- 回答:
因为 ++ 和 - - 在java使用情况是有歧义的。-->见第一章关于++ 和--的解析
何为歧义:指在不同的环境中表达的含义可能不同,导致混淆,所以scala不使用。
在scala中,使用 +=1 代替 ++
--拓展:
在中国奥运会开幕式上,采用了两种语言进行语音播报,中文和法语。
因为法语的语言逻辑是没有歧义的,一个词在任何环境下表达的意思的唯一的。4.4 逻辑运算符
假定变量 A 为 1,B 为 0

4.5 位运算
如果指定 A = 60及 B = 13; 两个变量对应的二进制为:A = 0011 1100,B = 0000 1101

二进制中,每位上的最大数为1
所以:
前提:byte类型
1111 1111 -->第一个1为符号位,表示负数,所以负数的最大值:-1
1000 0000 -->第一个1为符号位,表示负数,所以负数最小值为:-128byte b = 127 ;
b = (byte) (b + 1) ;
System.out.println(b); //-128
/*
过程解析:
b=127 --> 0111 1111 【byte类型】
b+1 --> 0000 0000 0000 0000 0000 0000 1000 0000 【类型自动转换至int类型】
byte(b+1) --> 截断,只取 1000 0000 -->-128位运算的用处:源码中使用了位运算,查看源码时用的着。
4.6 运算符的本质
-- scala 运算符介绍
1. scala是一个完全面向对象的语言;
2. 在scala语言中,万物皆对象;
3. 数字其实就是数值类型的对象;
4. scala没有运算符,所有的运算符都是方法。
-- scala 运算符使用技巧
1. '.' 点号可以省略;
2. () 小括号如果没有参数或者只有一个参数,可以省略。 //例题1
val i1 = 2.+(3)
val i2 = 2 + 3
//这就是技巧的运用,首先2是一个Int对象,'.' 表示调用方法,可以省略,又因为只有一个参数3,所以()也省略,所以上面两个代码是完全等同的。
println(i1) //5
println(i2) //5
//例题2
val s = "abc" * 2 //等价于: "abc".*(2)
println(s) //abcabc
//例题3:
1.to(2)
1 to 2五、流程控制
5.1 分支控制
分支控制一共分为单支、双支和多支控制三种情况。
5.1.1 单分支
-- 语法:
if(布尔表达式) {
// 如果布尔表达式为 true 则执行该语句块
}5.1.2 双分支
--语法:
if(布尔表达式) {
// 如果布尔表达式为 true 则执行该语句块
} else {
// 如果布尔表达式为 false 则执行该语句块
}5.1.3 多分支
--语法:
if(布尔表达式1) {
// 如果布尔表达式1为 true,则执行该语句块
} else if ( 布尔表达式2 ) {
// 如果布尔表达式2为 true,则执行该语句块
}...
} else {
// 上面条件都不满足的场合,则执行该语句块
}5.1.4 表达式的返回值
-- 说明:
scala中所有的表达式都是有返回值的。
-- 问题1:什么是表达式?
如:
println(i) --> 方法表达式
10 == 10 --> 逻辑表达式
3 + 2 --> 算术表达式
a = 10 --> 赋值表达式
-- 问题2:返回值类型怎么确定?
1.如果表达式结果的类型只有一种,那么表达式返回值的类型与其相等;
2.如果表达式结果的类型只有多种,那么表达式返回值的类型与其所有结果类型的父类类型相等。
3.说明:for()和while()循环没有返回值。所以类型为Unit
-- 问题3:表达式的结果是什么?
返回值取决于"满足条件"的"最后一行"代码的结果。
如果不是条件表达式,那么返回值则为表达式的结果。// 例题1:
val unit = println(i) // 返回值类型:Unit , 返回值类型:()
// 例题2:
val b = 10 == 10 // 返回值类型:Boolean ,返回值:true
// 例题3:
val result = if (age < 20) {
println("少年")
} else {
println("壮年")
}
//返回值类型:Unit,返回值类型:()
// 例题4:
val age = 20
val result = if (age < 20) {
"少年"
} else {
println("壮年")
}
//返回值类型:Any,返回值为:()
// 例题5:
val age = 20
val result = if (age < 20) {
"少年"
println("少年")
} else {
println("壮年")
}
//返回值类型:Unit,返回值为:()
// 例题6
val result= for (i <- 1 to 5) {
i
}
//返回值类型:Unit,返回值为()
// 例题7
val i = 1
val r = if(i > 20){
i
}
//返回值类型:AnyVal 返回值为:()- 问题
-- 为什么scala中没有三元运算符
-- 回答
在java中的三元运算符如下:
String s = age > 20 ? "Tina" : "China"
为避免符号的特殊含义,所以scala中没有三元运算符,而是使用if .. else来代替5.1.5 if .. else 的简化
val result = if (age > 20) {
20
} else {
19
}
//第一步:如果大括号里面只有一行代码,那么就可以省略大括号
val result = if (age > 20) 20 else 195.1.6 分号的简化
-- 如果一行代码中只有一段逻辑,可以省略分号;
-- 如果一行代码中有多段逻辑,则不能省略
如: printl(s)
printl(s);printl(s)5.2 循环控制

5.2.1 for 循环
- java中的for循环
//方式1:普通for循环
for (int i = 0 ; i < 100 ;i++ ) { 逻辑语句 }
//方式2:增强for循环
for(Object obj : List) { 逻辑语句 }- scala中的for循环
5.2.1.1 方式一:默认循环方式
for (i <- 1 to 5) {
print(i)
}
/*
运行结果:12345
代码解析:
1. 1 to 5 --> 1.to(5) --> [1,2,3,4,5]
2. <- : 指向赋值,将集合中的值一个一个的赋值给到i
3. i : 没有声明类型,自动推断5.2.1.2 方式二:设定步长
for (i <- 1 to 5 by 2) {
print(i)
}
/*
运行结果:135
解析:
1. 1 to 5 by 2 --> by 步长,默认是一个一个进行赋值,使用了by 2 以后,则步长为2 -->赋值为i的数:[1,3,5]5.2.1.3 方式三:不取右端的值
for (i <- 1 until 5){
print(i)
}
/*
运算结果:1234
解析:
1. 1 until 5 --> 1.until(5) --> [1,2,3,4,5) , 5不取值5.2.1.4 方式四: 使用rang方式:rang (start , end )
rang (start , end ) = start until end
for (i <- Range(1,5)){
print(i)
}
/*
运行结果:1234
解析:
1. range(1,5) <==> 1 until 5 -->[1,2,3,4,5)5.2.1.5 方式五:rang (start , end ,step)
for (i <- Range(1,5,2)){
print(i)
}
/*
运行结果:13
解析:
1. rang(start ,end , step) : step表示步长5.2.1.6 循环守卫
for (i <- Range(1,5) if i != 3){
println(i)
}
/*
运行结果:124
解析:
1.(i <- Range(1,5) if i != 3)内有两段逻辑,但是没有使用分号,
请联想if else的优化【val result = if (age > 20) 20 else 19】,是不是一样的情况呢?因为关键词,编译器能够自动识别。
2. if != 3 --> i不能等于3,换句话说,等于3的不要。5.2.1.7 嵌套循环
-- 格式:
for (外层循环,内层循环) { 循环体 }//方式1
for (i <- 1 to 5 ; j <- 1 to 4 ){
println(j)
}
//<==============等价于如下逻辑==============>
//方式2
for (i <- 1 to 5) {
for (j <- 1 to 4) {
println(j)
}
}
/*
对比如上两种方式:
方式1 比 方式2 代码上看来更简洁,但是代码1具有局限性,循环体只能是内层循环的循环体,没有办法体现外层的循环体。5.2.1.8 引入变量
//例题1:
for (i <- 1 to 2; j = i + 1) {
println(j)
}//例题2
/*
用一层for循环求9层妖塔
*
***
*****
*******
*********
***********
*************
***************
*****************
*/
val num = 9
for (i <- 1 to num ; j = 2 * i -1 ; m = 9 - i){
println(" " * m + "*" * j)
}5.2.1.9 for循环返回值
//表达式都有返回值
// 举例1:
var m = 10
val result = m = 20
println(result) //返回值类型:Unit ,返回值:()
// 举例2:
while((i = read.line()) != -1 ) {方法体} // 死循环- 关于for循环的返回值
1. for循环的表达式的返回值为Unit
2. 如果想要获取for循环表达式中循环体的返回,使用yield关键字 val r = for(i <- 1 to 3 ) yield{
i*2
}
println(r)
/*
运行结果:Vector(2, 4, 6) -->一个向量集合
1. yeild就是"获取循环体中的返回值"。
2. 这种情况的使用场景:可以将一个集合转换为另一个集合,但是开发中并不会这么使用,因为后面集合中有更好的方法可以实现这种需求。- 问题:java线程中有yield方法,scala如果想调用java中的yield方法怎么处理?
Thread.`yield`()5.2.2 while 循环
5.2.2.1 while语法
//语法:
方式1:
while (循环条件表达式) {
循环体
}
//方式2:
do {
循环体
}while (循环条件表达式)5.2.2.2 循环中断
-- java中,在循环中会使用 break (结束循环) 和 continue (结束本次循环) 来中断循环。
-- scala中因为是完全面向对象编程,所以没有如上两个关键词,那怎么办呢?
1. 在scala中认为continue是非常鸡肋的,因为结束本次循环只需要使用if进行判断就可以,所以在scala中没有单独实现continue功能;
2. 在scala中实现break的方式:对象.方法 --》scala.util.control.Breaks.break();
3. 当导入'scala.util.control.Breaks._'包时,Break对象可以省略。
--中断的实现方式:
1. "实现方式":依赖于抛出异常的方式来中断循环,导致抛出异常后面的代码不会再被执行,那如何进行优化呢?
2. "优化方式":scala将需要中断的循环体放置在一个代码块中Breaks.breakable{中断的代码},可以处理抛出的异常
3. "再说明":breakable是一个方法,{}其实是一个参数列表,将一段代码的执行结果作为参数传递给一个方法。import scala.util.control.Breaks
/**
* @Description
* *
* @author lianzhipeng
* @create 2020-05-20 15:11:16
*/
object Scala_Method {
def main(args: Array[String]): Unit = {
val m = 10
while (m <= 10) {
println(m)
if (m == 10) {
Breaks.break()
}
println(m)
}
}
/*输出结果:
10
Exception in thread "main" scala.util.control.BreakControl- 优化
val m = 10
Breaks.breakable {
while (m <= 10) {
println(m)
if (m == 10) {
Breaks.break()
}
}
}
println(m)
//输出结果: 10 10六、函数式编程
6.1 函数编程简介
什么是函数式编程?
将问题分解成一个一个的步骤,将每个步骤进行封装(函数),通过调用这些封装好的功能按照指定的步骤,解决问题。
函数和方法的区别
-- 基本说明
1. 方法是java中的概念,函数是scala中的概念;
2. scala是完全面向对象编程的语言,所以函数也是对象;
3. 一般情况下,直接在类中封装的功能称为方法,其他地方均称为函数;
4. 函数可以声明在任何地方。
-- 使用上的差异:
1. 函数可以嵌套声明,但是方法不行;
2. 方法有重载和重写,但是函数没有,'在同一个作用域内,只要函数名称相同,则认为该函数已经声明过,直接报错'。
-- 总结:
方法也是函数,只是因为声明的位置不同,所以具有一些特性'重载和重写'。6.2 函数定义和使用 --普通班
6.2.1 函数的声明和调用
- 函数的声明
// 格式:
权限修饰符 函数名 (参数列表) : 返回值类型 = { 函数体 }
// 案例:
def func(i:Int) : Unit = {
println(i)
}
//权限修饰暂时不讲,后面会讲- 函数的调用
函数名(形参类表)6.2.2 函数的定义
一共有如下6种情况:
无参 --> 无返回值、有返回值
有参 --> 无返回值、有返回值
多参 --> 无返回值、有返回值
-- 再单独讲述一下可变形参object Scala_Method {
def main(args: Array[String]): Unit = {
//无参 -- 无返回值
def func1 () :Unit = {
println("scala")
}
// func1()
//无参 -- 有返回值
def func2 () :String = {
"lianzhipeng"
}
val str = func2()
// println(str)
//有参 -- 无返回值
def func3 (i : Int ) : Unit = {
println(i)
}
// func3(20)
//有参 -- 有返回值
def func4 (i : Int) : String = {
"我今年是" + i + "岁"
}
val str1 = func4(18)
// println(str1)
//多参 -- 无返回值
def func5(name:String,age:Int) : Unit = {
println(s"name=`$`{name},age =`$`age")
}
// func5("lianzhipeng",18)
//多参 -- 有返回值
def func6(x:Int,y:Int):Int = {
x-y
}
val i = func6(30,26)
println(i) //4
}
}6.2.3 可变参数
函数参数的个数
1)一个函数形参的个数最多为22;
2)在声明和调用函数时,形参个数超过22是没有问题的,但是将函数作为对象赋值给一个变量时,则会报错:implementation restricts functions to 22 parameters

- 可变形参
1. 相同类型的参数出现多个,但是不确定个数时,使用可变参数
2. 表示方式 (i : Int * ) -->变量类型*
3. 可变参数放置在形参类表的最后位置 -->所以一个形参类列中只能有一个可变形参
4. 可变形参变量是一个集合,可以通过遍历的方式获取传入的每一个值 def func1(i : Int* ) : Unit = {
for (m <- i ) {
println(m)
}
}
func1(1,2,3,74)
//运行结果:1 2 3 74 def func1(i: Int*): Unit = {
println(i)
}
func1() //List()
func1(1) //WrappedArray(1)
func1(1, 2, 3, 74) //WrappedArray(1, 2, 3, 74)6.2.4 参数列表的默认值
1. scala中函数的参数是使用val进行声明的,所以不可变;
2. scala中函数提供了参数默认值的语法来解决这个不可变的问题;
3. 有默认值的参数,可以在调用函数时不传参数,则此时函数使用的是参数的默认值;
4. 如果调用函数时,给有默认值的参数进行传参数了,那么会将参数的默认值进行覆盖;- 问题1:如何给参数进行设定默认值呢?
//在形参列表中给参数进行初始化
def func3(i : Int = 1) : Unit = {
println(i)
}- 问题2:如果形参类表中有些有参数,有些没有参数,而且在形参列表中的顺序不是连续,传参数时,如何进行区分是传递给哪个形参呢?
--原则有二
原则一:函数在传递参数时,是从左到右依次进行匹配;
原则二:使用带名参数,指明给哪个参数进行传递参数。
-- 问题:那什么是带名参数呢?见下小节解析6.2.5 带名参数
/*调用函数时使用注意事项:
1.如果想跳过默认值对参数传参,则需要带名
2.因为传参数是按照从左到右的顺序,所以如果前面的形参已经传参数了,那么就可以不需要带名
*/
def fun4(i :Int , name :String ="lianzhipeng",age : Int, nation : String = "China") : Unit = {
}
fun4(20,age=20)6.3 函数至简原则--噩梦班
讲述scala中函数的至简原则:能省则省。
def func1 () : String = {
return "China"
}
//首先将如上函数进行划分如下7个模块
1. def :函数或方法声明的关键字
2. func1 : 函数名
3. () : 形参列表
4. String :返回值类型
5. = :赋值操作符号
6. {} : 花括号,包裹函数体
7. return "China" : 函数体
//接下就是对这7个部分的省略的原则 --惊心动魄的历程,好好享受吧。6.3.1 return省略
7. return "China" : 函数体
//省略原则:当函数需要返回值时,都是将函数体中最后执行的代码作为返回结果,所以可以省略 return 关键字
//省略return后代码:
def func1 () : String = {
"China"
}6.3.2 返回值类型省略
4. String : 返回值类型
//省略原则:如果编译可以推断出函数类型的返回值类型,则返回值类型可以省略
//优化后:
def func1 () = {
"China"
}6.3.3 { } 省略
6. {} : 花括号,包裹函数体
//省略原则:如果函数体只有一段逻辑代码,那么大括号是可以省略
理解:什么是一段逻辑代码:经过验证发现 if else 代码可以作为一段代码, for ()循环也可以作为一段代码,但是这种一段代码我们一般不会将{}省略,我们在使用过程中,函数体中只有一行代码且只有一段逻辑时,我们采取省略{}
// 优化后:
def func1 () = "China"
//关于if else 结构的省略--【一般不这么用,作为了解】
def func5(i: Int) =
if (i > 10)
"i > 10"
else
"i <= 10"
//关于for() 结构的省略--【一般不这么用,作为了解】
def func5(i: Int) =
for (i <- 0 to i ) {i; println(i)}6.3.4 形参列表()省略
3. () : 形参列表
//省略原则:当形参列表中没有参数时,可以省略()
说明:声明函数和调用函数是否需要带'()'
1. 如果声明的函数没有(),那么调用函数时就一定不能有;
2. 如果声明的函数中有(),那么调用函数时就可以有也可以没有。
"总结:调用函数时,()与声明的函数保持一致就准没错"
特例:如果是将函数以对象的方式赋值给一个变量,那么通过变量调用函数时,()不能省去。
//优化后
def func1 = "China"到此为止,是不是发现和变量声明方式及其相似,只是关键字不同。
def fun = "lianzhipeng "
val name = "lianzhipeng"6.3.5 过程函数
--本小节讲述 return 与Unit 的藕断丝连
1. 假如返回值类型是Unit,并且显示定义了,那么函数体的return关键字不起作用。
--什么是不起作用?
就是Unit不接收你return返回的数据,但是return依然可以起结束函数的作用。
2. 之前说到return关键字可以省略,是因为return的地方一定是方法执行的最后一段代码'当然可能是多个位置,如条件表达式,不知道走哪个分支,但是每个分支如果执行,都是函数执行的最后一段代码'。
--那么问题是:如果我们显示的声明了return关键词,你的返回值类型就不能省略。
3. 由此引出了过程函数的概念
--显示声明return,希望返回值是Unit,但又不想显示声明Unit,那么怎么办?
采取省略 = 等号的方式实现这个需求。--> 这样的函数,咱们就称为是过程函数。如下:
def fun {return "lianzhipeng "}
//问题来了:
1. {}能不能省略?这逻辑代码不是只有一行吗?
-- 答案:不能省略
2. 现在返回值类型明确是Unit,函数不接收return的返回值,那我这个return有啥作用呢?
-- 答案: 此时,咱们一般不会写返回值的内容,因为没有任何作用,此时return可以用来改变逻辑分支使用。6.3.6 匿名函数
-- 什么是匿名函数
当只关心代码逻辑,不关心函数名称时,函数名称和def关键字均可以省略,此时,这个函数没有名称和关键字,咱们就称这种函数为匿名函数。-- 匿名函数的格式:
(形参类表) => { 代码逻辑 }
-- 如果代码逻辑只有一行,那么 {} 是可以省略的。() => println("lianzhipeng")- 又来问题了:那我如何调用这个函数呢?
-- 解决方案:
将匿名函数作为一个对象赋值给一个变量。//将匿名函数赋值给一个变量
val function = () => println("lianzhipeng")
// 调用函数
function()注意事项:
() => println("lianzhipeng")
//将匿名函数赋值给一个变量
val function = () => println("lianzhipeng")
// 调用函数
function()
/*
解析:如上代码是不会被执行的。
原因是:第一行代码的匿名函数,因为没有变量来进行接收,那么在编译的过程中,编译器会将匿名函数及后续所有代码编译成一个匿名函数,因为匿名函数在编译中没有被调用,所以被编译到匿名函数中的代码是不会被执行的。6.4 函数高阶用途 -- 地狱班
所谓的高阶函数,其实就是将函数当成一个类型来使用,而不是当成特定的语法结构。
6.4.1 函数作为值
-- 函数可以作为对象赋值给变量。一共有两种方式def function1 (name : String , age : Int ) : String = "name=" + name + ",age=" + age
//方式一:使用 "函数名 _" 的方式
val func = function1 _
println(func("lianzhipeng", 20))
//方式二:指明变量的类型
//函数类型为:(参数列表每个参数的类型) => 返回值类型
val func1 : (String,Int) => String = function1
println(func1("lianzhipeng", 20))
//特别注意
val func = function1 //如果没有下划线也没有指明变量的类型,如果右边的函数无参的,则是将计算结果赋值给左边的变量,如果右边的函数有参数的,则直接报错。6.4.2 函数作为参数
-- 将封装好逻辑的函数,作为参数传递到其他函数中。
-- 格式:
函数名(函数名1:函数类型1,函数名2 : 函数类型) //准备一个基本函数1
def functions (i : Int) :Unit = println("age=" + i )
//将函数赋值给一个参数
val func = functions _
//准备另外一个函数2
def functions1 (f : Int => Unit , name : String) = f(10)
//调用函数2,并将函数1传入
functions1(func,"lianzhipeng")
/*
注意事项:
1)我们也可以不声明变量,使用函数名的方式将函数直接传入,此时加和不加下划线都是可以的,但是我们一般不这么用
*/
functions1(functions,"lianzhipeng")
functions1(functions _ ,lianzhipeng")简化
将 函数作为参数传递到另外一个函数中时,则不关心函数的名称,则此时我们可以使用匿名函数的方式。
//匿名函数: (形参列表) => {函数体}
(i:Int) => {println("age=" + i )}
//准备另外一个函数
def functions1 (f : Int => Unit , name : String) = f(10)
//调用函数,并将匿名函数传入
functions1((i:Int) => {println("age=" + i )},"lianzhipeng")- 至简原则
// 1. 如果匿名函数代码只有一行,则可以省略{}
functions1((i:Int) => println("age=" + i ),"lianzhipeng")
// 2. 如果匿名函数对象的参数类型可以推断出来时,那么匿名函数的参数类型可省略
functions1( (i) => println("age=" + i ),"lianzhipeng")
// 3. 如果匿名函数的参数列表只有一个或者没有,那么小括号也可以省去
functions1( i => println("age=" + i ),"lianzhipeng")
// 4. 如果匿名函数的函数体中的逻辑中只使用一次,则参数可以省略,并使用下划线代替
functions1( println("age=" + _ ),"lianzhipeng")




