定时任务 - 分布式xxl-job方式
定时任务 - 分布式xxl-job方式
除了前文介绍的ElasticJob,xxl-job在很多中小公司有着应用(虽然其代码和设计等质量并不太高,Licence不够开放,有着个人主义色彩,但是其具体开箱使用的便捷性和功能相对完善性,这是中小团队采用的主要原因);XXL-JOB是一个分布式任务调度平台,其核心设计目标是开发迅速、学习简单、轻量级、易扩展。本文介绍XXL-JOB以及SpringBoot的集成。
1. 知识准备
需要对分布式任务的知识体系和xxl-Job有基本的理解。
1.1 分布式任务知识体系
站在分布式任务知识体系的角度看分布式任务。
- 本文主要介绍定时任务的基础和单体方式下定时任务方案的演化,以及常见的分布式任务方案(包括Quartz Cluster,ElasticJob,xxl-job等)和技术实现要点。
1.2 什么是xxl-job
XXL-JOB是一个分布式任务调度平台,其核心设计目标是开发迅速、学习简单、轻量级、易扩展。现已开放源代码并接入多家公司线上产品线,开箱即用。如下内容来源于xxl-job官网
支持如下特性:
- 1、简单:支持通过Web页面对任务进行CRUD操作,操作简单,一分钟上手;
- 2、动态:支持动态修改任务状态、启动/停止任务,以及终止运行中任务,即时生效;
- 3、调度中心HA(中心式):调度采用中心式设计,“调度中心”自研调度组件并支持集群部署,可保证调度中心HA;
- 4、执行器HA(分布式):任务分布式执行,任务"执行器"支持集群部署,可保证任务执行HA;
- 5、注册中心: 执行器会周期性自动注册任务, 调度中心将会自动发现注册的任务并触发执行。同时,也支持手动录入执行器地址;
- 6、弹性扩容缩容:一旦有新执行器机器上线或者下线,下次调度时将会重新分配任务;
- 7、触发策略:提供丰富的任务触发策略,包括:Cron触发、固定间隔触发、固定延时触发、API(事件)触发、人工触发、父子任务触发;
- 8、调度过期策略:调度中心错过调度时间的补偿处理策略,包括:忽略、立即补偿触发一次等;
- 9、阻塞处理策略:调度过于密集执行器来不及处理时的处理策略,策略包括:单机串行(默认)、丢弃后续调度、覆盖之前调度;
- 10、任务超时控制:支持自定义任务超时时间,任务运行超时将会主动中断任务;
- 11、任务失败重试:支持自定义任务失败重试次数,当任务失败时将会按照预设的失败重试次数主动进行重试;其中分片任务支持分片粒度的失败重试;
- 12、任务失败告警;默认提供邮件方式失败告警,同时预留扩展接口,可方便的扩展短信、钉钉等告警方式;
- 13、路由策略:执行器集群部署时提供丰富的路由策略,包括:第一个、最后一个、轮询、随机、一致性HASH、最不经常使用、最近最久未使用、故障转移、忙碌转移等;
- 14、分片广播任务:执行器集群部署时,任务路由策略选择"分片广播"情况下,一次任务调度将会广播触发集群中所有执行器执行一次任务,可根据分片参数开发分片任务;
- 15、动态分片:分片广播任务以执行器为维度进行分片,支持动态扩容执行器集群从而动态增加分片数量,协同进行业务处理;在进行大数据量业务操作时可显著提升任务处理能力和速度。
- 16、故障转移:任务路由策略选择"故障转移"情况下,如果执行器集群中某一台机器故障,将会自动Failover切换到一台正常的执行器发送调度请求。
- 17、任务进度监控:支持实时监控任务进度;
- 18、Rolling实时日志:支持在线查看调度结果,并且支持以Rolling方式实时查看执行器输出的完整的执行日志;
- 19、GLUE:提供Web IDE,支持在线开发任务逻辑代码,动态发布,实时编译生效,省略部署上线的过程。支持30个版本的历史版本回溯。
- 20、脚本任务:支持以GLUE模式开发和运行脚本任务,包括Shell、Python、NodeJS、PHP、PowerShell等类型脚本;
- 21、命令行任务:原生提供通用命令行任务Handler(Bean任务,"CommandJobHandler");业务方只需要提供命令行即可;
- 22、任务依赖:支持配置子任务依赖,当父任务执行结束且执行成功后将会主动触发一次子任务的执行, 多个子任务用逗号分隔;
- 23、一致性:“调度中心”通过DB锁保证集群分布式调度的一致性, 一次任务调度只会触发一次执行;
- 24、自定义任务参数:支持在线配置调度任务入参,即时生效;
- 25、调度线程池:调度系统多线程触发调度运行,确保调度精确执行,不被堵塞;
- 26、数据加密:调度中心和执行器之间的通讯进行数据加密,提升调度信息安全性;
- 27、邮件报警:任务失败时支持邮件报警,支持配置多邮件地址群发报警邮件;
- 28、推送maven中央仓库: 将会把最新稳定版推送到maven中央仓库, 方便用户接入和使用;
- 29、运行报表:支持实时查看运行数据,如任务数量、调度次数、执行器数量等;以及调度报表,如调度日期分布图,调度成功分布图等;
- 30、全异步:任务调度流程全异步化设计实现,如异步调度、异步运行、异步回调等,有效对密集调度进行流量削峰,理论上支持任意时长任务的运行;
- 31、跨语言:调度中心与执行器提供语言无关的 RESTful API 服务,第三方任意语言可据此对接调度中心或者实现执行器。除此之外,还提供了 “多任务模式”和“httpJobHandler”等其他跨语言方案;
- 32、国际化:调度中心支持国际化设置,提供中文、英文两种可选语言,默认为中文;
- 33、容器化:提供官方docker镜像,并实时更新推送dockerhub,进一步实现产品开箱即用;
- 34、线程池隔离:调度线程池进行隔离拆分,慢任务自动降级进入"Slow"线程池,避免耗尽调度线程,提高系统稳定性;
- 35、用户管理:支持在线管理系统用户,存在管理员、普通用户两种角色;
- 36、权限控制:执行器维度进行权限控制,管理员拥有全量权限,普通用户需要分配执行器权限后才允许相关操作;
1.3 xxl-job的架构设计
1.3.1 设计思想
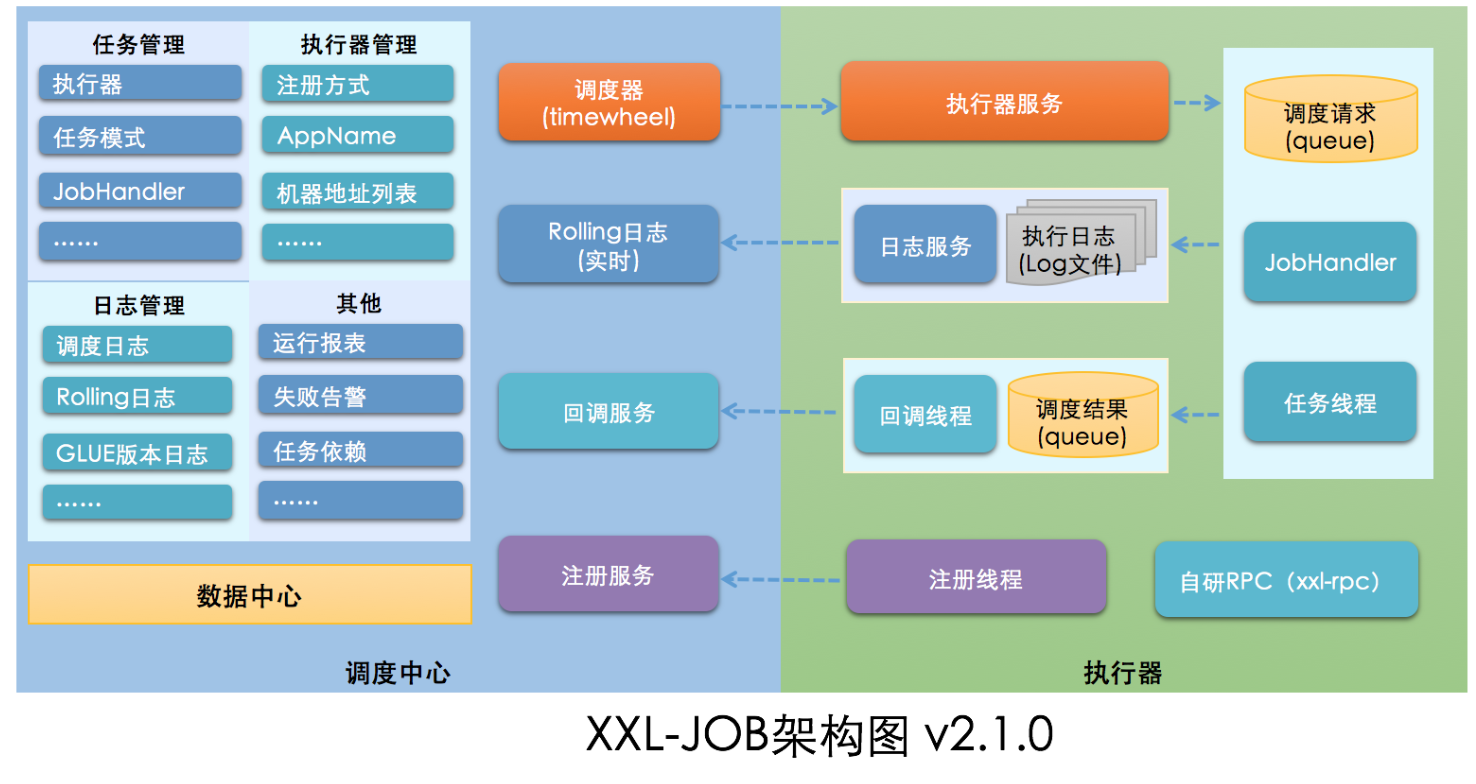
将调度行为抽象形成“调度中心”公共平台,而平台自身并不承担业务逻辑,“调度中心”负责发起调度请求。
将任务抽象成分散的JobHandler,交由“执行器”统一管理,“执行器”负责接收调度请求并执行对应的JobHandler中业务逻辑。
因此,“调度”和“任务”两部分可以相互解耦,提高系统整体稳定性和扩展性;
1.3.2 系统组成
- 调度模块(调度中心)
- 负责管理调度信息,按照调度配置发出调度请求,自身不承担业务代码。调度系统与任务解耦,提高了系统可用性和稳定性,同时调度系统性能不再受限于任务模块;
- 支持可视化、简单且动态的管理调度信息,包括任务新建,更新,删除,GLUE开发和任务报警等,所有上述操作都会实时生效,同时支持监控调度结果以及执行日志,支持执行器Failover。
- 执行模块(执行器):
- 负责接收调度请求并执行任务逻辑。任务模块专注于任务的执行等操作,开发和维护更加简单和高效;
- 接收“调度中心”的执行请求、终止请求和日志请求等。
1.3.3 架构图
2. 实现案例
主要介绍SpringBoot集成xxl-job的方式:Bean模式(基于方法和基于类); 以及基于在线配置代码/脚本的GLUE模式。
2.1 Bean模式(基于方法)
Bean模式任务,支持基于方法的开发方式,每个任务对应一个方法。基于方法开发的任务,底层会生成JobHandler代理,和基于类的方式一样,任务也会以JobHandler的形式存在于执行器任务容器中。
优点:
- 每个任务只需要开发一个方法,并添加”@XxlJob”注解即可,更加方便、快速。
- 支持自动扫描任务并注入到执行器容器。
缺点:要求Spring容器环境;
2.1.1 Job的开发环境依赖
Maven 依赖
<dependency>
<groupId>com.xuxueli</groupId>
<artifactId>xxl-job-core</artifactId>
<version>2.3.1</version>
</dependency>application.properties配置
# web port
server.port=8081
# no web
#spring.main.web-environment=false
# log config
logging.config=classpath:logback.xml
### xxl-job admin address list, such as "http://address" or "http://address01,http://address02"
xxl.job.admin.addresses=http://127.0.0.1:8080/xxl-job-admin
### xxl-job, access token
xxl.job.accessToken=default_token
### xxl-job executor appname
xxl.job.executor.appname=xxl-job-executor-sample
### xxl-job executor registry-address: default use address to registry , otherwise use ip:port if address is null
xxl.job.executor.address=
### xxl-job executor server-info
xxl.job.executor.ip=
xxl.job.executor.port=9999
### xxl-job executor log-path
xxl.job.executor.logpath=/data/applogs/xxl-job/jobhandler
### xxl-job executor log-retention-days
xxl.job.executor.logretentiondays=30Config配置(PS:这里我是直接拿的xxl-job demo中的配置,实际开发中可以封装一个starter自动注入)
package tech.pdai.springboot.xxljob.config;
import com.xxl.job.core.executor.impl.XxlJobSpringExecutor;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* xxl-job config
*
* @author xuxueli 2017-04-28
*/
@Configuration
public class XxlJobConfig {
private Logger logger = LoggerFactory.getLogger(XxlJobConfig.class);
@Value("${xxl.job.admin.addresses}")
private String adminAddresses;
@Value("${xxl.job.accessToken}")
private String accessToken;
@Value("${xxl.job.executor.appname}")
private String appname;
@Value("${xxl.job.executor.address}")
private String address;
@Value("${xxl.job.executor.ip}")
private String ip;
@Value("${xxl.job.executor.port}")
private int port;
@Value("${xxl.job.executor.logpath}")
private String logPath;
@Value("${xxl.job.executor.logretentiondays}")
private int logRetentionDays;
@Bean
public XxlJobSpringExecutor xxlJobExecutor() {
logger.info(">>>>>>>>>>> xxl-job config init.");
XxlJobSpringExecutor xxlJobSpringExecutor = new XxlJobSpringExecutor();
xxlJobSpringExecutor.setAdminAddresses(adminAddresses);
xxlJobSpringExecutor.setAppname(appname);
xxlJobSpringExecutor.setAddress(address);
xxlJobSpringExecutor.setIp(ip);
xxlJobSpringExecutor.setPort(port);
xxlJobSpringExecutor.setAccessToken(accessToken);
xxlJobSpringExecutor.setLogPath(logPath);
xxlJobSpringExecutor.setLogRetentionDays(logRetentionDays);
// Bean方法模式
// 通过扫描@XxlJob方式注册
// 注册Bean类模式
XxlJobExecutor.registJobHandler("beanClassDemoJobHandler", new BeanClassDemoJob());
return xxlJobSpringExecutor;
}
}2.1.2 Job的开发
开发步骤:
- 任务开发:在Spring Bean实例中,开发Job方法;
- 注解配置:为Job方法添加注解 "@XxlJob(value="自定义jobhandler名称", init = "JobHandler初始化方法", destroy = "JobHandler销毁方法")",注解value值对应的是调度中心新建任务的JobHandler属性的值。
- 执行日志:需要通过 "XxlJobHelper.log" 打印执行日志;
- 任务结果:默认任务结果为 "成功" 状态,不需要主动设置;如有诉求,比如设置任务结果为失败,可以通过 "XxlJobHelper.handleFail/handleSuccess" 自主设置任务结果;
package tech.pdai.springboot.xxljob.job;
import java.io.BufferedInputStream;
import java.io.BufferedReader;
import java.io.DataOutputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.Arrays;
import com.xxl.job.core.context.XxlJobHelper;
import com.xxl.job.core.handler.annotation.XxlJob;
import lombok.extern.slf4j.Slf4j;
import org.springframework.stereotype.Component;
/**
* XxlJob开发示例(Bean模式 - 方法)
*
*/
@Slf4j
@Component
public class BeanMethodDemoJob {
/**
* 1、简单任务示例(Bean模式)
*/
@XxlJob("demoJobHandler")
public void demoJobHandler() {
XxlJobHelper.log("demoJobHandler execute...");
}
/**
* 2、分片广播任务
*/
@XxlJob("shardingJobHandler")
public void shardingJobHandler() throws Exception {
// logback console日志
log.info("shardingJobHandler execute...");
// 通过xxl记录到DB中的日志
XxlJobHelper.log("shardingJobHandler execute...");
// 分片参数
int shardIndex = XxlJobHelper.getShardIndex();
int shardTotal = XxlJobHelper.getShardTotal();
XxlJobHelper.log("分片参数:当前分片序号 = {}, 总分片数 = {}", shardIndex, shardTotal);
// 业务逻辑
for (int i = 0; i < shardTotal; i++) {
if (i==shardIndex) {
XxlJobHelper.log("第 {} 片, 命中分片开始处理", i);
} else {
XxlJobHelper.log("第 {} 片, 忽略", i);
}
}
}
/**
* 3、命令行任务
*/
@XxlJob("commandJobHandler")
public void commandJobHandler() throws Exception {
XxlJobHelper.log("commandJobHandler execute...");
String command = XxlJobHelper.getJobParam();
int exitValue = -1;
BufferedReader bufferedReader = null;
try {
// command process
ProcessBuilder processBuilder = new ProcessBuilder();
processBuilder.command(command);
processBuilder.redirectErrorStream(true);
Process process = processBuilder.start();
//Process process = Runtime.getRuntime().exec(command);
BufferedInputStream bufferedInputStream = new BufferedInputStream(process.getInputStream());
bufferedReader = new BufferedReader(new InputStreamReader(bufferedInputStream));
// command log
String line;
while ((line = bufferedReader.readLine())!=null) {
XxlJobHelper.log(line);
}
// command exit
process.waitFor();
exitValue = process.exitValue();
} catch (Exception e) {
XxlJobHelper.log(e);
} finally {
if (bufferedReader!=null) {
bufferedReader.close();
}
}
if (exitValue==0) {
// default success
} else {
XxlJobHelper.handleFail("command exit value(" + exitValue + ") is failed");
}
}
/**
* 4、跨平台Http任务
* 参数示例:
* "url: http://www.baidu.com\n" +
* "method: get\n" +
* "data: content\n";
*/
@XxlJob("httpJobHandler")
public void httpJobHandler() throws Exception {
XxlJobHelper.log("httpJobHandler execute...");
// param parse
String param = XxlJobHelper.getJobParam();
if (param==null || param.trim().length()==0) {
XxlJobHelper.log("param[" + param + "] invalid.");
XxlJobHelper.handleFail();
return;
}
String[] httpParams = param.split("\n");
String url = null;
String method = null;
String data = null;
for (String httpParam : httpParams) {
if (httpParam.startsWith("url:")) {
url = httpParam.substring(httpParam.indexOf("url:") + 4).trim();
}
if (httpParam.startsWith("method:")) {
method = httpParam.substring(httpParam.indexOf("method:") + 7).trim().toUpperCase();
}
if (httpParam.startsWith("data:")) {
data = httpParam.substring(httpParam.indexOf("data:") + 5).trim();
}
}
// param valid
if (url==null || url.trim().length()==0) {
XxlJobHelper.log("url[" + url + "] invalid.");
XxlJobHelper.handleFail();
return;
}
if (method==null || !Arrays.asList("GET", "POST").contains(method)) {
XxlJobHelper.log("method[" + method + "] invalid.");
XxlJobHelper.handleFail();
return;
}
boolean isPostMethod = method.equals("POST");
// request
HttpURLConnection connection = null;
BufferedReader bufferedReader = null;
try {
// connection
URL realUrl = new URL(url);
connection = (HttpURLConnection) realUrl.openConnection();
// connection setting
connection.setRequestMethod(method);
connection.setDoOutput(isPostMethod);
connection.setDoInput(true);
connection.setUseCaches(false);
connection.setReadTimeout(5 * 1000);
connection.setConnectTimeout(3 * 1000);
connection.setRequestProperty("connection", "Keep-Alive");
connection.setRequestProperty("Content-Type", "application/json;charset=UTF-8");
connection.setRequestProperty("Accept-Charset", "application/json;charset=UTF-8");
// do connection
connection.connect();
// data
if (isPostMethod && data!=null && data.trim().length() > 0) {
DataOutputStream dataOutputStream = new DataOutputStream(connection.getOutputStream());
dataOutputStream.write(data.getBytes("UTF-8"));
dataOutputStream.flush();
dataOutputStream.close();
}
// valid StatusCode
int statusCode = connection.getResponseCode();
if (statusCode!=200) {
throw new RuntimeException("Http Request StatusCode(" + statusCode + ") Invalid.");
}
// result
bufferedReader = new BufferedReader(new InputStreamReader(connection.getInputStream(), "UTF-8"));
StringBuilder result = new StringBuilder();
String line;
while ((line = bufferedReader.readLine())!=null) {
result.append(line);
}
String responseMsg = result.toString();
XxlJobHelper.log(responseMsg);
return;
} catch (Exception e) {
XxlJobHelper.log(e);
XxlJobHelper.handleFail();
return;
} finally {
try {
if (bufferedReader!=null) {
bufferedReader.close();
}
if (connection!=null) {
connection.disconnect();
}
} catch (Exception e2) {
XxlJobHelper.log(e2);
}
}
}
/**
* 5、生命周期任务示例:任务初始化与销毁时,支持自定义相关逻辑;
*/
@XxlJob(value = "demoJobHandler2", init = "init", destroy = "destroy")
public void demoJobHandler2() throws Exception {
XxlJobHelper.log("demoJobHandler2, execute...");
}
public void init() {
log.info("init");
}
public void destroy() {
log.info("destroy");
}
}( 从设计的角度,xxl-job可以对上述不同类型进行细分)
2.1.3 Job的调度配置和执行
新增Job, 并把上述的@XxlJob(value="自定义jobhandler名称", init = "JobHandler初始化方法", destroy = "JobHandler销毁方法")中 自定义jobhandler名称 填写到JobHandler中。
其它配置如下:
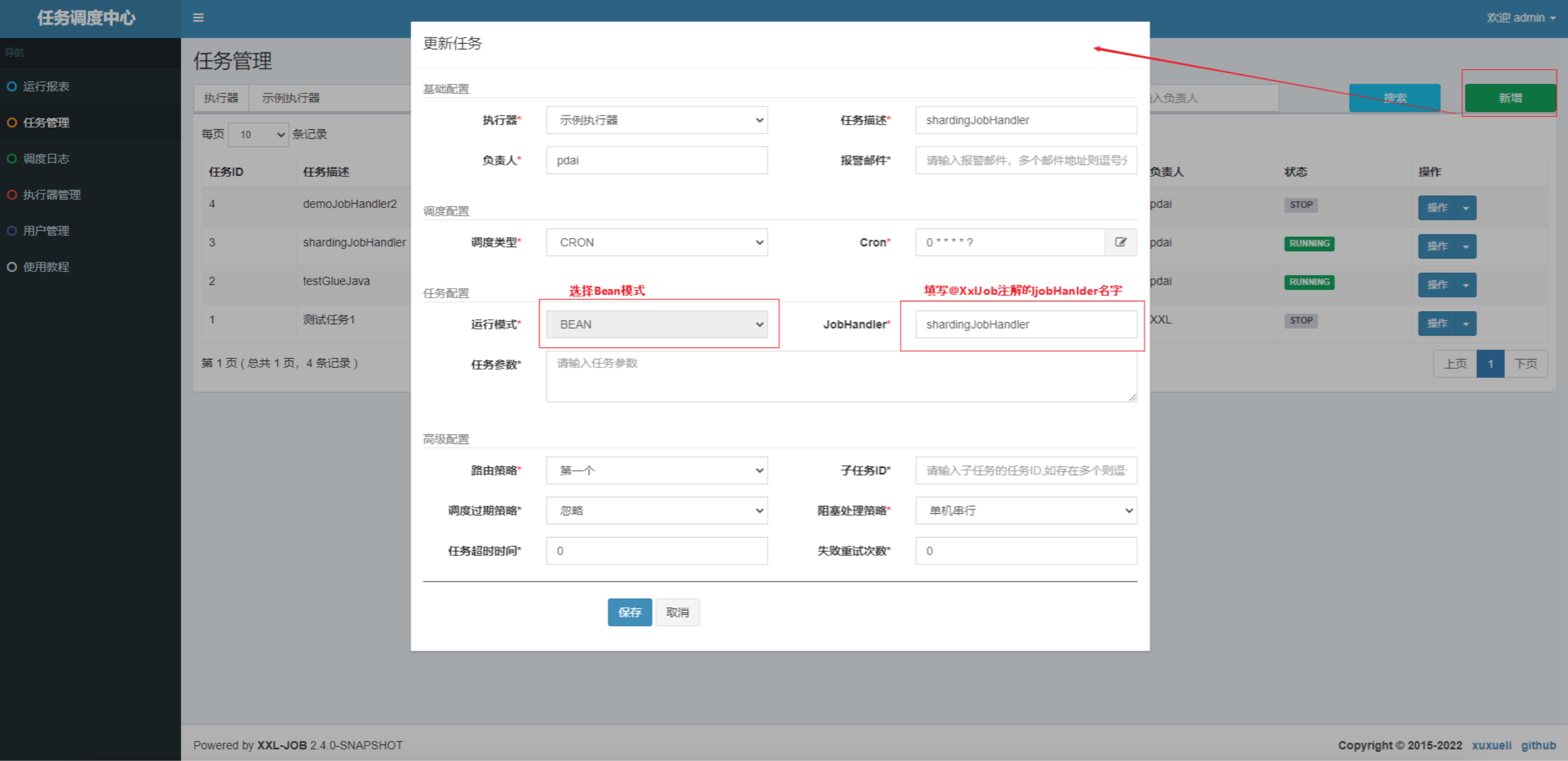
可以选择操作中执行一次任务,或者启动(按照Cron执行)
可以查看执行的记录
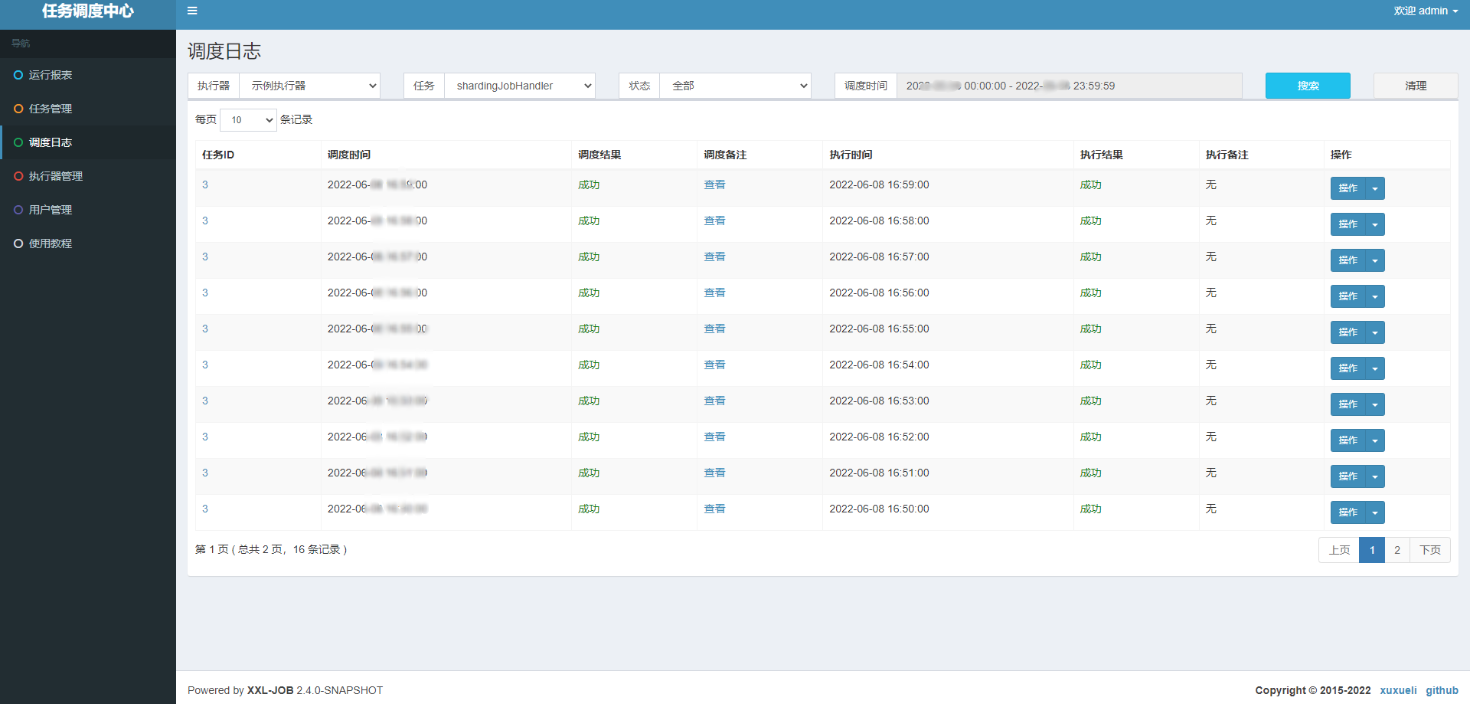
进一步可以看每个执行记录的执行日志
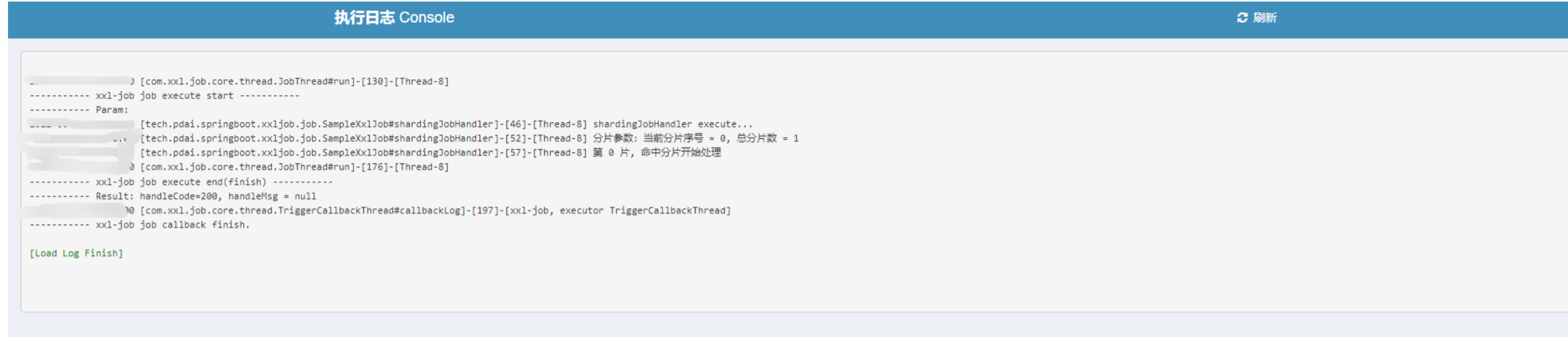
2.2 Bean模式(基于类)
Bean模式任务,支持基于类的开发方式,每个任务对应一个Java类。
优点:不限制项目环境,兼容性好。即使是无框架项目,如main方法直接启动的项目也可以提供支持,可以参考示例项目 “xxl-job-executor-sample-frameless”;
缺点:
- 每个任务需要占用一个Java类,造成类的浪费;
- 不支持自动扫描任务并注入到执行器容器,需要手动注入。
2.2.1 Job的开发环境依赖
同Bean模式(基于方法)
2.2.2 Job的开发
开发步骤:
- 执行器项目中,开发Job类:
- 开发一个继承自"com.xxl.job.core.handler.IJobHandler"的JobHandler类,实现其中任务方法。
- 手动通过如下方式注入到执行器容器。
- 注册jobHandler
XxlJobExecutor.registJobHandler("xxxxxJobHandler", new xxxxxJobHandler());
Job开发
package tech.pdai.springboot.xxljob.job;
import com.xxl.job.core.handler.IJobHandler;
import lombok.extern.slf4j.Slf4j;
/**
* @author pdai
*/
@Slf4j
public class BeanClassDemoJob extends IJobHandler {
@Override
public void execute() throws Exception {
log.info("BeanClassDemoJob, execute...");
}
}注册jobHandler( 这里xxl-job设计的不好,是可以通过IJobHandler来自动注册的)
XxlJobExecutor.registJobHandler("beanClassDemoJobHandler", new BeanClassDemoJob());启动SpringBoot应用, 可以发现注册的
...
20:34:15.385 logback [main] INFO c.x.job.core.executor.XxlJobExecutor - >>>>>>>>>>> xxl-job register jobhandler success, name:beanClassDemoJobHandler, jobHandler:tech.pdai.springboot.xxljob.job.BeanClassDemoJob@640ab13c
...2.2.3 ob的调度配置和执行
同Bean模式(基于方法)
在调度器中添加执行后,后台执行的日志如下:
20:41:00.021 logback [xxl-job, EmbedServer bizThreadPool-1023773196] INFO c.x.job.core.executor.XxlJobExecutor - >>>>>>>>>>> xxl-job regist JobThread success, jobId:5, handler:tech.pdai.springboot.xxljob.job.BeanClassDemoJob@640ab13c
20:41:00.022 logback [xxl-job, JobThread-5-1654681260021] INFO t.p.s.xxljob.job.BeanClassDemoJob - BeanClassDemoJob, execute...2.3 GLUE模式
任务以源码方式维护在调度中心,支持通过Web IDE在线更新,实时编译和生效,因此不需要指定JobHandler。
2.3.1 配置和启动流程
开发流程如下:
创建GLUE类型的Job(这里以Java为例)
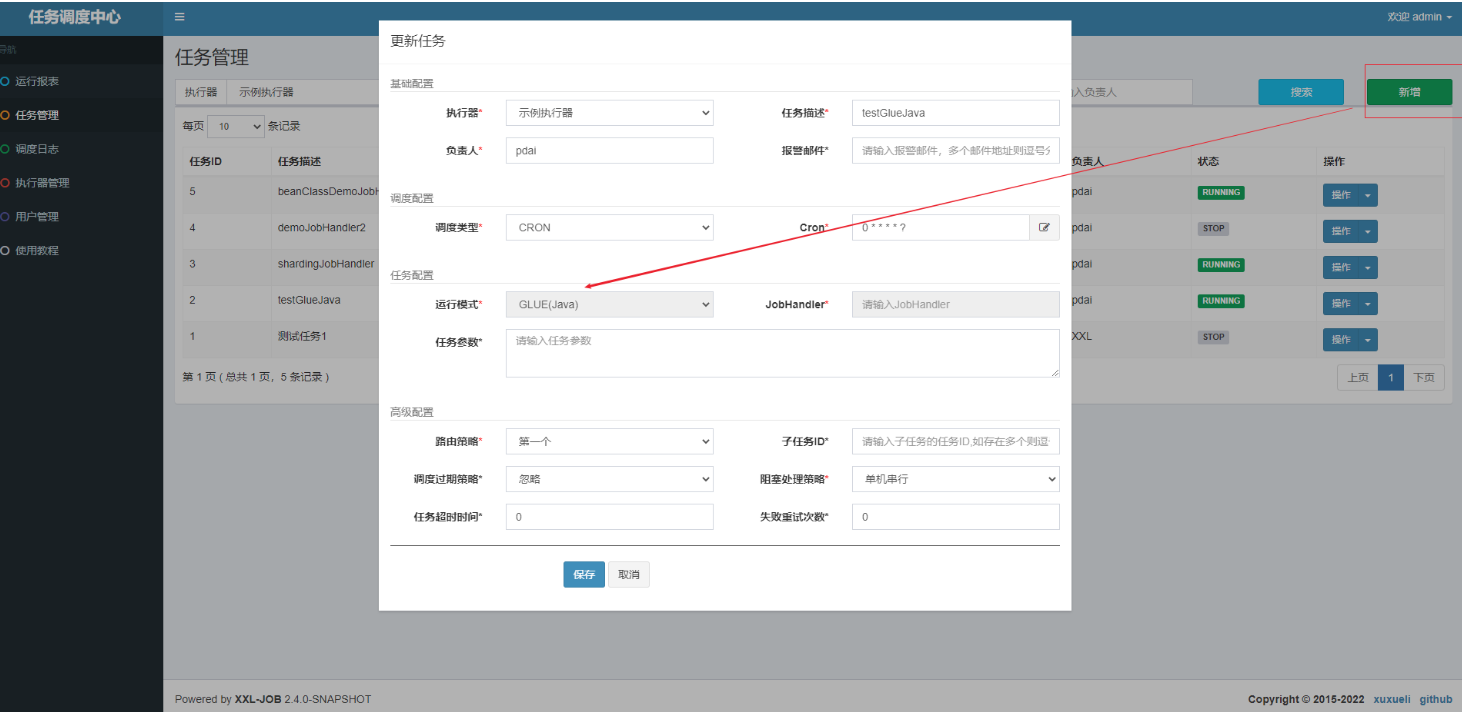
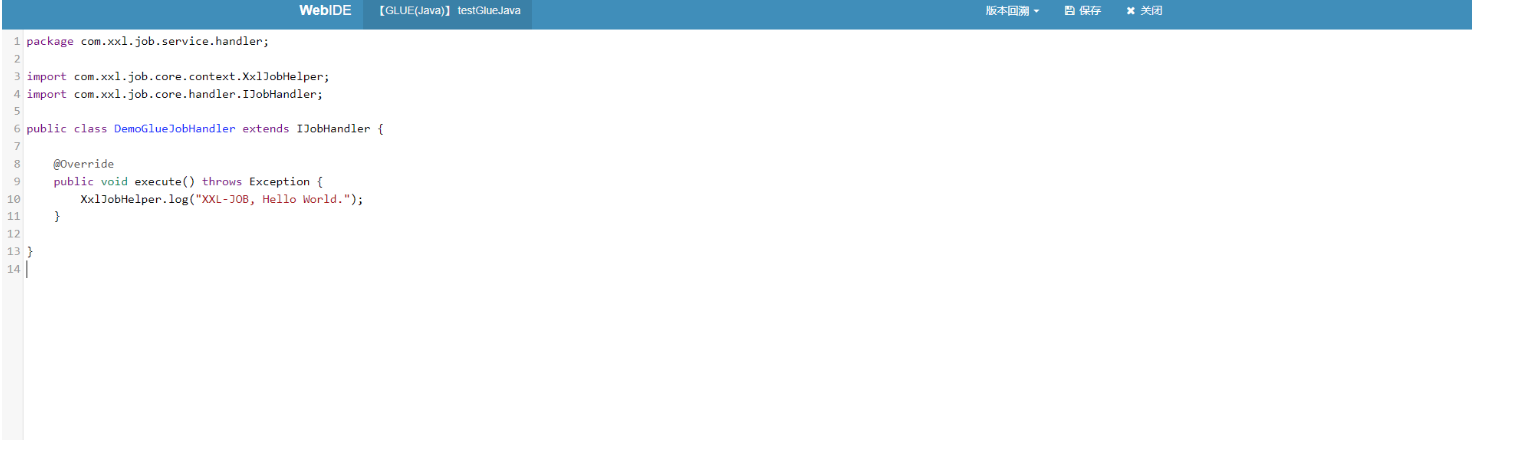
选中指定任务,点击该任务右侧“GLUE”按钮,将会前往GLUE任务的Web IDE界面,在该界面支持对任务代码进行开发(也可以在IDE中开发完成后,复制粘贴到编辑中)。
版本回溯功能(支持30个版本的版本回溯):在GLUE任务的Web IDE界面,选择右上角下拉框“版本回溯”,会列出该GLUE的更新历史,选择相应版本即可显示该版本代码,保存后GLUE代码即回退到对应的历史版本;
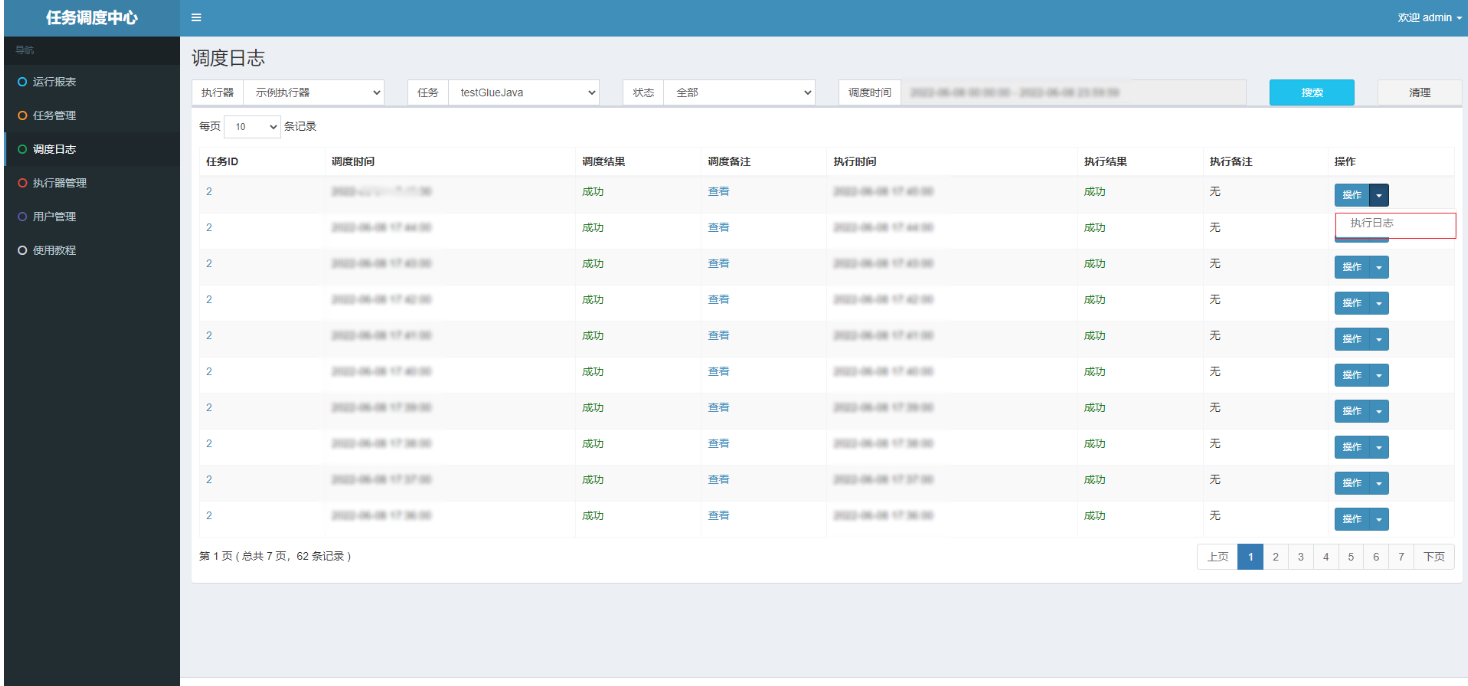
执行后的记录如下
2.3.2 GLUE模式还有哪些
xxl-job一共支持如下几种GLUE模式:
- GLUE模式(Java):任务以源码方式维护在调度中心;该模式的任务实际上是一段继承自IJobHandler的Java类代码并 "groovy" 源码方式维护,它在执行器项目中运行,可使用@Resource/@Autowire注入执行器里中的其他服务;
- GLUE模式(Shell):任务以源码方式维护在调度中心;该模式的任务实际上是一段 "shell" 脚本;
- GLUE模式(Python):任务以源码方式维护在调度中心;该模式的任务实际上是一段 "python" 脚本;
- GLUE模式(PHP):任务以源码方式维护在调度中心;该模式的任务实际上是一段 "php" 脚本;
- GLUE模式(NodeJS):任务以源码方式维护在调度中心;该模式的任务实际上是一段 "nodejs" 脚本;
- GLUE模式(PowerShell):任务以源码方式维护在调度中心;该模式的任务实际上是一段 "PowerShell" 脚本;
3. 更多配置的说明
+ 基础配置:
- 执行器:任务的绑定的执行器,任务触发调度时将会自动发现注册成功的执行器, 实现任务自动发现功能; 另一方面也可以方便的进行任务分组。每个任务必须绑定一个执行器, 可在 "执行器管理" 进行设置;
- 任务描述:任务的描述信息,便于任务管理;
- 负责人:任务的负责人;
- 报警邮件:任务调度失败时邮件通知的邮箱地址,支持配置多邮箱地址,配置多个邮箱地址时用逗号分隔;
+ 触发配置:
- 调度类型:
+ 无:该类型不会主动触发调度;
+ CRON:该类型将会通过CRON,触发任务调度;
+ 固定速度:该类型将会以固定速度,触发任务调度;按照固定的间隔时间,周期性触发;
+ 固定延迟:该类型将会以固定延迟,触发任务调度;按照固定的延迟时间,从上次调度结束后开始计算延迟时间,到达延迟时间后触发下次调度;
- CRON:触发任务执行的Cron表达式;
- 固定速度:固件速度的时间间隔,单位为秒;
- 固定延迟:固件延迟的时间间隔,单位为秒;
+ 高级配置:
- 路由策略:当执行器集群部署时,提供丰富的路由策略,包括;
FIRST(第一个):固定选择第一个机器;
LAST(最后一个):固定选择最后一个机器;
ROUND(轮询):;
RANDOM(随机):随机选择在线的机器;
CONSISTENT_HASH(一致性HASH):每个任务按照Hash算法固定选择某一台机器,且所有任务均匀散列在不同机器上。
LEAST_FREQUENTLY_USED(最不经常使用):使用频率最低的机器优先被选举;
LEAST_RECENTLY_USED(最近最久未使用):最久未使用的机器优先被选举;
FAILOVER(故障转移):按照顺序依次进行心跳检测,第一个心跳检测成功的机器选定为目标执行器并发起调度;
BUSYOVER(忙碌转移):按照顺序依次进行空闲检测,第一个空闲检测成功的机器选定为目标执行器并发起调度;
SHARDING_BROADCAST(分片广播):广播触发对应集群中所有机器执行一次任务,同时系统自动传递分片参数;可根据分片参数开发分片任务;
- 子任务:每个任务都拥有一个唯一的任务ID(任务ID可以从任务列表获取),当本任务执行结束并且执行成功时,将会触发子任务ID所对应的任务的一次主动调度。
- 调度过期策略:
- 忽略:调度过期后,忽略过期的任务,从当前时间开始重新计算下次触发时间;
- 立即执行一次:调度过期后,立即执行一次,并从当前时间开始重新计算下次触发时间;
- 阻塞处理策略:调度过于密集执行器来不及处理时的处理策略;
单机串行(默认):调度请求进入单机执行器后,调度请求进入FIFO队列并以串行方式运行;
丢弃后续调度:调度请求进入单机执行器后,发现执行器存在运行的调度任务,本次请求将会被丢弃并标记为失败;
覆盖之前调度:调度请求进入单机执行器后,发现执行器存在运行的调度任务,将会终止运行中的调度任务并清空队列,然后运行本地调度任务;
- 任务超时时间:支持自定义任务超时时间,任务运行超时将会主动中断任务;
- 失败重试次数;支持自定义任务失败重试次数,当任务失败时将会按照预设的失败重试次数主动进行重试;




