Java IO - 源码: InputStream
...大约 14 分钟
Java IO - 源码: InputStream
本文主要从JDK 11 源码角度分析InputStream。
1. InputStream 类实现关系
InputStream是输入字节流,具体的实现类层次结构如下:
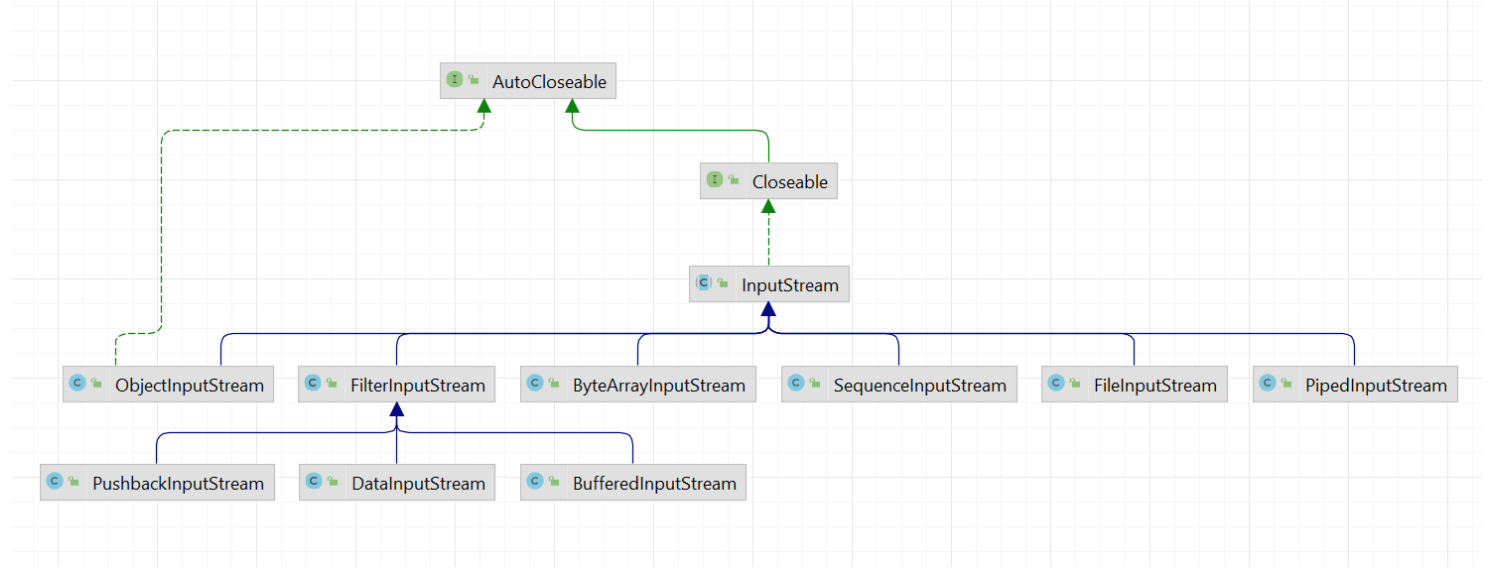
2. InputStream 抽象类
InputStream 类重要方法设计如下:
// 读取下一个字节,如果没有则返回-1
public abstract int read()
// 将读取到的数据放在 byte 数组中,该方法实际上调用read(byte b[], int off, int len)方法
public int read(byte b[])
// 从第 off 位置读取<b>最多(实际可能小于)</b> len 长度字节的数据放到 byte 数组中,流是以 -1 来判断是否读取结束的; 此方法会一直阻止,直到输入数据可用、检测到stream结尾或引发异常为止。
public int read(byte b[], int off, int len)
// JDK9新增:读取 InputStream 中的所有剩余字节,调用readNBytes(Integer.MAX_VALUE)方法
public byte[] readAllBytes()
// JDK11更新:读取 InputStream 中的剩余字节的指定上限大小的字节内容;此方法会一直阻塞,直到读取了请求的字节数、检测到流结束或引发异常为止。此方法不会关闭输入流。
public byte[] readNBytes(int len)
// JDK9新增:从输入流读取请求的字节数并保存在byte数组中; 此方法会一直阻塞,直到读取了请求的字节数、检测到流结束或引发异常为止。此方法不会关闭输入流。
public int readNBytes(byte[] b, int off, int len)
// 跳过指定个数的字节不读取
public long skip(long n)
// 返回可读的字节数量
public int available()
// 读取完,关闭流,释放资源
public void close()
// 标记读取位置,下次还可以从这里开始读取,使用前要看当前流是否支持,可以使用 markSupport() 方法判断
public synchronized void mark(int readlimit)
// 重置读取位置为上次 mark 标记的位置
public synchronized void reset()
// 判断当前流是否支持标记流,和上面两个方法配套使用
public boolean markSupported()
// JDK9新增:读取 InputStream 中的全部字节并写入到指定的 OutputStream 中
public long transferTo(OutputStream out)2. 源码实现
梳理部分InputStream及其实现类的源码分析。
2.1 InputStream
InputStream抽象类源码如下:
public abstract class InputStream implements Closeable {
// 当使用skip方法时,最大的buffer size大小
private static final int MAX_SKIP_BUFFER_SIZE = 2048;
// 默认的buffer size
private static final int DEFAULT_BUFFER_SIZE = 8192;
// JDK11中增加了一个nullInputStream,即空模式实现,以便可以直接调用而不用判空(可以看如下的补充说明)
public static InputStream nullInputStream() {
return new InputStream() {
private volatile boolean closed;
private void ensureOpen() throws IOException {
if (closed) {
throw new IOException("Stream closed");
}
}
@Override
public int available () throws IOException {
ensureOpen();
return 0;
}
@Override
public int read() throws IOException {
ensureOpen();
return -1;
}
@Override
public int read(byte[] b, int off, int len) throws IOException {
Objects.checkFromIndexSize(off, len, b.length);
if (len == 0) {
return 0;
}
ensureOpen();
return -1;
}
@Override
public byte[] readAllBytes() throws IOException {
ensureOpen();
return new byte[0];
}
@Override
public int readNBytes(byte[] b, int off, int len)
throws IOException {
Objects.checkFromIndexSize(off, len, b.length);
ensureOpen();
return 0;
}
@Override
public byte[] readNBytes(int len) throws IOException {
if (len < 0) {
throw new IllegalArgumentException("len < 0");
}
ensureOpen();
return new byte[0];
}
@Override
public long skip(long n) throws IOException {
ensureOpen();
return 0L;
}
@Override
public long transferTo(OutputStream out) throws IOException {
Objects.requireNonNull(out);
ensureOpen();
return 0L;
}
@Override
public void close() throws IOException {
closed = true;
}
};
}
// 读取下一个字节的数据,如果没有则返回-1
public abstract int read() throws IOException;
// 将读取到的数据放在 byte 数组中,该方法实际上调用read(byte b[], int off, int len)方法
public int read(byte b[]) throws IOException {
return read(b, 0, b.length);
}
// 从第 off 位置读取<b>最多(实际可能小于)</b> len 长度字节的数据放到 byte 数组中,流是以 -1 来判断是否读取结束的; 此方法会一直阻止,直到输入数据可用、检测到stream结尾或引发异常为止。
public int read(byte b[], int off, int len) throws IOException {
// 检查边界
Objects.checkFromIndexSize(off, len, b.length);
if (len == 0) {
return 0;
}
// 读取下一个字节
int c = read();
if (c == -1) { // 读到stream末尾,则返回读取的字节数量为-1
return -1;
}
b[off] = (byte)c;
// i用来记录取了多少个字节
int i = 1;
try {
// 循环读取
for (; i < len ; i++) {
c = read();
if (c == -1) {// 读到stream末尾,则break
break;
}
b[off + i] = (byte)c;
}
} catch (IOException ee) {
}
// 返回读取到的字节个数
return i;
}
// 分配的最大数组大小。
// 由于一些VM在数组中保留一些头字,所以尝试分配较大的阵列可能会导致OutOfMemoryError(请求的阵列大小超过VM限制)
private static final int MAX_BUFFER_SIZE = Integer.MAX_VALUE - 8;
// JDK9新增:读取 InputStream 中的所有剩余字节,调用readNBytes(Integer.MAX_VALUE)方法
public byte[] readAllBytes() throws IOException {
return readNBytes(Integer.MAX_VALUE);
}
// JDK11更新:读取 InputStream 中的剩余字节的指定上限大小的字节内容;此方法会一直阻塞,直到读取了请求的字节数、检测到流结束或引发异常为止。此方法不会关闭输入流。
public byte[] readNBytes(int len) throws IOException {
// 边界检查
if (len < 0) {
throw new IllegalArgumentException("len < 0");
}
List<byte[]> bufs = null; // 缓存每次读取到的内容放到bufs,最后组装成result
byte[] result = null; // 最后读取到的内容
int total = 0;
int remaining = len; // 剩余字节长度
int n;
do {
byte[] buf = new byte[Math.min(remaining, DEFAULT_BUFFER_SIZE)];
int nread = 0;
// 读取到结束为止,读取大小n可能大于或小于缓冲区大小
while ((n = read(buf, nread,
Math.min(buf.length - nread, remaining))) > 0) {
nread += n;
remaining -= n;
}
if (nread > 0) {
if (MAX_BUFFER_SIZE - total < nread) {
throw new OutOfMemoryError("Required array size too large");
}
total += nread;
if (result == null) {
result = buf;
} else {
if (bufs == null) {
bufs = new ArrayList<>();
bufs.add(result);
}
bufs.add(buf);
}
}
// 如果读不到内容(返回-1)或者没有剩余的字节,则跳出循环
} while (n >= 0 && remaining > 0);
if (bufs == null) {
if (result == null) {
return new byte[0];
}
return result.length == total ?
result : Arrays.copyOf(result, total);
}
// 组装最后的result
result = new byte[total];
int offset = 0;
remaining = total;
for (byte[] b : bufs) {
int count = Math.min(b.length, remaining);
System.arraycopy(b, 0, result, offset, count);
offset += count;
remaining -= count;
}
return result;
}
// JDK9新增:从输入流读取请求的字节数并保存在byte数组中; 此方法会一直阻塞,直到读取了请求的字节数、检测到流结束或引发异常为止。此方法不会关闭输入流。
public int readNBytes(byte[] b, int off, int len) throws IOException {
Objects.checkFromIndexSize(off, len, b.length);
int n = 0;
while (n < len) {
int count = read(b, off + n, len - n);
if (count < 0)
break;
n += count;
}
return n;
}
// 跳过指定个数的字节不读取
public long skip(long n) throws IOException {
long remaining = n;
int nr;
if (n <= 0) {
return 0;
}
int size = (int)Math.min(MAX_SKIP_BUFFER_SIZE, remaining);
byte[] skipBuffer = new byte[size];
while (remaining > 0) {
nr = read(skipBuffer, 0, (int)Math.min(size, remaining));
if (nr < 0) {
break;
}
remaining -= nr;
}
return n - remaining;
}
// 返回可读的字节数量
public int available() throws IOException {
return 0;
}
// 读取完,关闭流,释放资源
public void close() throws IOException {}
// 标记读取位置,下次还可以从这里开始读取,使用前要看当前流是否支持,可以使用 markSupport() 方法判断
public synchronized void mark(int readlimit) {}
// 重置读取位置为上次 mark 标记的位置
public synchronized void reset() throws IOException {
throw new IOException("mark/reset not supported");
}
// 判断当前流是否支持标记流,和上面两个方法配套使用。默认是false,由子类方法重写
public boolean markSupported() {
return false;
}
// JDK9新增:读取 InputStream 中的全部字节并写入到指定的 OutputStream 中
public long transferTo(OutputStream out) throws IOException {
Objects.requireNonNull(out, "out");
long transferred = 0;
byte[] buffer = new byte[DEFAULT_BUFFER_SIZE];
int read;
while ((read = this.read(buffer, 0, DEFAULT_BUFFER_SIZE)) >= 0) {
out.write(buffer, 0, read);
transferred += read;
}
return transferred;
}总结下JDK9的更新点
类 java.io.InputStream 中增加了新的方法来读取和复制 InputStream 中包含的数据。
readAllBytes:读取 InputStream 中的所有剩余字节。readNBytes: 从 InputStream 中读取指定数量的字节到数组中。transferTo:读取 InputStream 中的全部字节并写入到指定的 OutputStream 中 。
public class TestInputStream {
private InputStream inputStream;
private static final String CONTENT = "Hello World";
@Before
public void setUp() throws Exception {
this.inputStream =
TestInputStream.class.getResourceAsStream("/input.txt");
}
@Test
public void testReadAllBytes() throws Exception {
final String content = new String(this.inputStream.readAllBytes());
assertEquals(CONTENT, content);
}
@Test
public void testReadNBytes() throws Exception {
final byte[] data = new byte[5];
this.inputStream.readNBytes(data, 0, 5);
assertEquals("Hello", new String(data));
}
@Test
public void testTransferTo() throws Exception {
final ByteArrayOutputStream outputStream = new ByteArrayOutputStream();
this.inputStream.transferTo(outputStream);
assertEquals(CONTENT, outputStream.toString());
}
}read(byte[], int, int)和readNBytes(byte[], int, int)看似是实现的相同功能,为何会设计readNBytes方法呢?
这个问题可以参看这里
- read(byte[], int, int)是尝试读到最多len个bytes,但是读取到的内容长度可能是小于len的。
- readNBytes(byte[], int, int) 会一直(while循环)查找直到stream尾为止
举个例子:如果文本内容是12345<end>, read(s,0,10)是允许返回123的, 而readNbytes(s,0,10)会一直(while循环)查找直到stream尾为止,并返回12345.
补充下JDK11为什么会增加nullInputStream方法的设计?即空对象模式
- 空对象模式
举个例子:
public class MyParser implements Parser {
private static Action NO_ACTION = new Action() {
public void doSomething() { /* do nothing */ }
};
public Action findAction(String userInput) {
// ...
if ( /* we can't find any actions */ ) {
return NO_ACTION;
}
}
}然后便可以始终可以这么调用,而不用再判断空了
ParserFactory.getParser().findAction(someInput).doSomething();2.2 FilterInputStream
FilterInputStream 源码如下
public class FilterInputStream extends InputStream {
// 被装饰的inputStream
protected volatile InputStream in;
// 构造函数,注入被装饰的inputStream
protected FilterInputStream(InputStream in) {
this.in = in;
}
// 本质是调用被装饰的inputStream的方法
public int read() throws IOException {
return in.read();
}
public int read(byte b[]) throws IOException {
return read(b, 0, b.length);
}
public int read(byte b[], int off, int len) throws IOException {
return in.read(b, off, len);
}
public long skip(long n) throws IOException {
return in.skip(n);
}
public int available() throws IOException {
return in.available();
}
public void close() throws IOException {
in.close();
}
public synchronized void mark(int readlimit) {
in.mark(readlimit);
}
public synchronized void reset() throws IOException {
in.reset();
}
public boolean markSupported() {
return in.markSupported();
}
}为什么被装饰的inputStream是volatile类型的?
请参看: 关键字: volatile详解
2.3 ByteArrayInputStream
ByteArrayInputStream源码如下
public class ByteArrayInputStream extends InputStream {
// 内部保存的byte 数组
protected byte buf[];
// 读取下一个字节的数组下标,byte[pos]就是read获取的下个字节
protected int pos;
// mark的数组下标位置
protected int mark = 0;
// 保存的有效byte的个数
protected int count;
// 构造方法
public ByteArrayInputStream(byte buf[]) {
this.buf = buf;
this.pos = 0;
this.count = buf.length;
}
// 构造方法,带offset的
public ByteArrayInputStream(byte buf[], int offset, int length) {
this.buf = buf;
this.pos = offset;
this.count = Math.min(offset + length, buf.length);
this.mark = offset;
}
// 从流中读取下一个字节,没有读取到返回 -1
public synchronized int read() {
return (pos < count) ? (buf[pos++] & 0xff) : -1;
}
// 从第 off 位置读取<b>最多(实际可能小于)</b> len 长度字节的数据放到 byte 数组中,流是以 -1 来判断是否读取结束的
public synchronized int read(byte b[], int off, int len) {
// 边界检查
if (b == null) {
throw new NullPointerException();
} else if (off < 0 || len < 0 || len > b.length - off) {
throw new IndexOutOfBoundsException();
}
if (pos >= count) {
return -1;
}
int avail = count - pos;
if (len > avail) {
len = avail;
}
if (len <= 0) {
return 0;
}
// 从buf拷贝到byte 数组b中
System.arraycopy(buf, pos, b, off, len);
pos += len;
return len;
}
// 跳过指定个数的字节不读取
public synchronized long skip(long n) {
long k = count - pos;
if (n < k) {
k = n < 0 ? 0 : n;
}
pos += k;
return k;
}
// 还有稍稍byte在buffer中未读取,即总的count 减去 当前byte位置
public synchronized int available() {
return count - pos;
}
// 支持mark所以返回true
public boolean markSupported() {
return true;
}
// 在流中当前位置mark, readAheadLimit参数未使用
public void mark(int readAheadLimit) {
mark = pos;
}
// 重置流,即回到mark的位置
public synchronized void reset() {
pos = mark;
}
// 关闭ByteArrayInputStream不会产生任何动作
public void close() throws IOException {
}
}2.4 BufferedInputStream
BufferedInputStream源码如下
public class BufferedInputStream extends FilterInputStream {
// 默认的buffer大小
private static int DEFAULT_BUFFER_SIZE = 8192;
// 分配的最大数组大小。
// 由于一些VM在数组中保留一些头字,所以尝试分配较大的阵列可能会导致OutOfMemoryError(请求的阵列大小超过VM限制)
private static int MAX_BUFFER_SIZE = Integer.MAX_VALUE - 8;
// 内部保存在byte 数组中
protected volatile byte buf[];
// 关闭流的方法可能是异步的,所以使用原子AtomicReferenceFieldUpdater提供CAS无锁方式(可以解决CAS的ABA问题)来保证
private static final AtomicReferenceFieldUpdater<BufferedInputStream, byte[]> bufUpdater =
AtomicReferenceFieldUpdater.newUpdater(BufferedInputStream.class, byte[].class, "buf");
// 有效byte的大小
protected int count;
// 当前位置
protected int pos;
// 最后一次,调用mark方法,标记的位置
protected int markpos = -1;
/**
* 该变量惟一入口就是mark(int readLimit),好比调用方法mark(1024),那么后面读取的数据若是
* 超过了1024字节,那么这次mark就为无效标记,子类能够选择抛弃该mark标记,从头开始。不过具体实现
* 跟具体的子类有关,在BufferedInputStream中,会抛弃mark标记,从新将markpos赋值为-1
*/
protected int marklimit;
// 获取被装饰的stream
private InputStream getInIfOpen() throws IOException {
InputStream input = in;
if (input == null)
throw new IOException("Stream closed");
return input;
}
// 获取实际内部的buffer数组
private byte[] getBufIfOpen() throws IOException {
byte[] buffer = buf;
if (buffer == null)
throw new IOException("Stream closed");
return buffer;
}
// 构造函数,buffer是8kb
public BufferedInputStream(InputStream in) {
this(in, DEFAULT_BUFFER_SIZE);
}
// 构造函数,指定buffer大小
public BufferedInputStream(InputStream in, int size) {
super(in);
if (size <= 0) {
throw new IllegalArgumentException("Buffer size <= 0");
}
buf = new byte[size];
}
/**
* 用更多的数据填充缓冲区,考虑到shuffling和其他处理标记的技巧,
* 假设它是由同步方法调用的。该方法还假设所有数据已经被读入,因此pos >count。
*/
private void fill() throws IOException {
// 得到内部缓冲区buffer
byte[] buffer = getBufIfOpen();
// 没有mark的情况下, pos为0
if (markpos < 0)
pos = 0; /* no mark: throw away the buffer */
// pos >= buffer.length buffer已经被读取完了
else if (pos >= buffer.length) /* no room left in buffer */
// markpos > 0 有标记,标记处在缓存中间
if (markpos > 0) { /* can throw away early part of the buffer */
// 把buffer中,markpos到pos的部分移动到0-sz处,pos设置为sz,markpos为0
int sz = pos - markpos;
System.arraycopy(buffer, markpos, buffer, 0, sz);
pos = sz;
markpos = 0;
// markpos已经为0了,marklimit比buffer.length小,再读取buffer已经没有地方了
} else if (buffer.length >= marklimit) {
// 清空缓存,清空标记,markpos为-1,pos为0
markpos = -1; /* buffer got too big, invalidate mark */
pos = 0; /* drop buffer contents */
// markpos已经为0了,marklimit比buffer.length大,而buffer.length已经最大了,不能扩容
} else if (buffer.length >= MAX_BUFFER_SIZE) {
throw new OutOfMemoryError("Required array size too large");
// markpos已经为0了,marklimit比buffer.length大
} else { /* grow buffer */
// 建立一个长度为min(2*pos,marklimit,MAX_BUFFER_SIZE),的缓存数组,然后把原来0-pos移动到新数组的0-pos处
int nsz = (pos <= MAX_BUFFER_SIZE - pos) ?
pos * 2 : MAX_BUFFER_SIZE;
if (nsz > marklimit)
nsz = marklimit;
byte nbuf[] = new byte[nsz];
System.arraycopy(buffer, 0, nbuf, 0, pos);
// 用bufUpdater替换buffer
if (!bufUpdater.compareAndSet(this, buffer, nbuf)) {
// Can't replace buf if there was an async close.
// Note: This would need to be changed if fill()
// is ever made accessible to multiple threads.
// But for now, the only way CAS can fail is via close.
// assert buf == null;
throw new IOException("Stream closed");
}
buffer = nbuf;
}
// 当前读取上限count为pos
count = pos;
// 从内部的输入流,读取pos到buffer.length部分,读取的字节数加到count
int n = getInIfOpen().read(buffer, pos, buffer.length - pos);
if (n > 0)
count = n + pos;
}
// 读取byte
public synchronized int read() throws IOException {
// 说明当前buf[]数组大小不够了,须要fill()
if (pos >= count) {
fill();
// 说明没有读取到任何数据
if (pos >= count)
return -1;
}
return getBufIfOpen()[pos++] & 0xff;
}
/**
* Read characters into a portion of an array, reading from the underlying
* stream at most once if necessary.
*/
private int read1(byte[] b, int off, int len) throws IOException {
int avail = count - pos;
if (avail <= 0) {
// 当写入指定数组b的长度大小超过BufferedInputStream中核心缓存数组buf[]的大小而且 markpos < 0,那么就直接从数据流中读取数据给b数组,而不经过buf[]缓存数组,避免buf[]数组急剧增大
if (len >= getBufIfOpen().length && markpos < 0) {
return getInIfOpen().read(b, off, len);
}
fill();
avail = count - pos;
if (avail <= 0) return -1;
}
int cnt = (avail < len) ? avail : len;
System.arraycopy(getBufIfOpen(), pos, b, off, cnt);
pos += cnt;
return cnt;
}
// 读取到byte数组b中
public synchronized int read(byte b[], int off, int len)
throws IOException
{
getBufIfOpen(); // Check for closed stream
if ((off | len | (off + len) | (b.length - (off + len))) < 0) {
throw new IndexOutOfBoundsException();
} else if (len == 0) {
return 0;
}
int n = 0;
for (;;) {
int nread = read1(b, off + n, len - n);
if (nread <= 0)
return (n == 0) ? nread : n;
n += nread;
if (n >= len)
return n;
// if not closed but no bytes available, return
InputStream input = in;
if (input != null && input.available() <= 0)
return n;
}
}
// 跳过n个
public synchronized long skip(long n) throws IOException {
getBufIfOpen(); // Check for closed stream
if (n <= 0) {
return 0;
}
long avail = count - pos;
if (avail <= 0) {
// If no mark position set then don't keep in buffer
if (markpos <0)
return getInIfOpen().skip(n);
// Fill in buffer to save bytes for reset
fill();
avail = count - pos;
if (avail <= 0)
return 0;
}
long skipped = (avail < n) ? avail : n;
pos += skipped;
return skipped;
}
// buf[]数组剩余字节数+输入流中剩余字节数
public synchronized int available() throws IOException {
int n = count - pos;
int avail = getInIfOpen().available();
return n > (Integer.MAX_VALUE - avail)
? Integer.MAX_VALUE
: n + avail;
}
// 标记位置,marklimit只有在这里才可以被赋值,readlimit表示mark()方法执行后,最多可以从流中读取的数据
// 若是超过该字节大小,那么在fill()的时候,就会认为此mark()标记无效,从新将 markpos = -1,pos = 0
public synchronized void mark(int readlimit) {
marklimit = readlimit;
markpos = pos;
}
// 重置位置
public synchronized void reset() throws IOException {
getBufIfOpen(); // 如果已经close, 则直接报错
if (markpos < 0)
throw new IOException("Resetting to invalid mark");
pos = markpos;
}
// 支持mark, 所以返回true
public boolean markSupported() {
return true;
}
// 通过AtomicReferenceFieldUpdater的CAS无锁方式close
public void close() throws IOException {
byte[] buffer;
while ( (buffer = buf) != null) {
if (bufUpdater.compareAndSet(this, buffer, null)) {
InputStream input = in;
in = null;
if (input != null)
input.close();
return;
}
// Else retry in case a new buf was CASed in fill()
}
}
}AtomicReferenceFieldUpdater具体可以参考:JUC原子类: CAS, Unsafe和原子类详解
参考文章
赞助





