Solr配置中文分词器ik-analyzer
...大约 2 分钟
Solr配置中文分词器ik-analyzer
1. 背景
2. 集成步骤
下载ik分词器
将jar包放入Solr服务的
Jetty或Tomcat的webapp/WEB-INF/lib/目录下;默认位置:E:\solr-7.7\solr-7.7.3\server\solr-webapp\webapp\WEB-INF\lib
将
resources目录下的5个配置文件放入solr服务的Jetty或Tomcat的webapp/WEB-INF/classes/目录下;① IKAnalyzer.cfg.xml ② ext.dic ③ stopword.dic ④ ik.conf ⑤ dynamicdic.txt配置Solr的
managed-schema,添加ik分词器,示例如下;<!-- ik分词器 --> <fieldType name="text_ik" class="solr.TextField"> <analyzer type="index"> <tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="false" conf="ik.conf"/> <filter class="solr.LowerCaseFilterFactory"/> </analyzer> <analyzer type="query"> <tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="true" conf="ik.conf"/> <filter class="solr.LowerCaseFilterFactory"/> </analyzer> </fieldType>配置完成,重启服务
solr stop -all solr start启动Solr服务测试分词
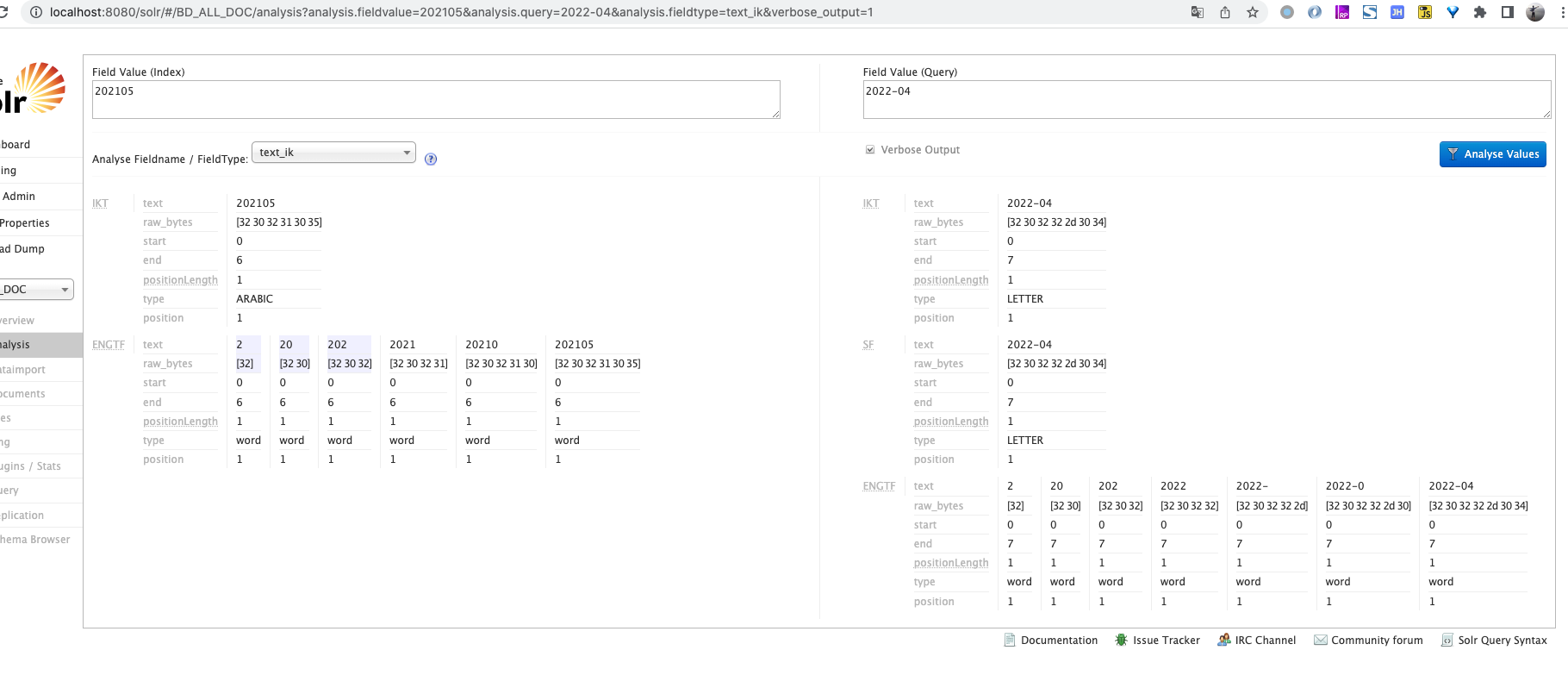
选择core-> Analysis -> 选择分词器 text_ik 输入 "黑夜给了我黑色的眼睛"->点击"Analyse Values"按钮

image-20210304172543651
3. ik分词器配置
ik.conf文件说明:files=dynamicdic.txt lastupdate=0files为动态词典列表,可以设置多个词典表,用逗号进行分隔,默认动态词典表为dynamicdic.txt;lastupdate默认值为0,每次对动态词典表修改后请+1,不然不会将词典表中新的词语添加到内存中。
dynamicdic.txt为动态词典在此文件配置的词语不需重启服务即可加载进内存中。 以
#开头的词语视为注释,将不会加载到内存中。
4. 设置同义词或停止词
4.1 同义词示例
例如在利用word分词后,查询“下跌”,得到结果如下:
4.1.1 没有同义词的情况
查询“下跌”,找到一片文档

查询“下降”是没有结果的:

4.1.2 同义词配置
在synonyms.txt配置:下降=>下跌
或者设置为:下降,下跌
前者表示为将下降转换为下跌,后者表示这些词可以相互替换。
# Some synonym groups specific to this example
GB,gib,gigabyte,gigabytes
MB,mib,megabyte,megabytes
Television, Televisions, TV, TVs
# 用逗号和=>都可以
# 下降,下跌
下降=>都可以下跌另外,还要记得在相应的fieldType加上对同义词的支持:
<fieldType name="text_general" class="solr.TextField" positionIncrementGap="100" multiValued="true">
<analyzer type="index">
<tokenizer class="org.apdplat.word.solr.ChineseWordTokenizerFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="org.apdplat.word.solr.ChineseWordTokenizerFactory"/>
<filter class="solr.SynonymFilterFactory" expand="true" ignoreCase="true" synonyms="synonyms.txt"/>
</analyzer>4.1.3 重启后生效
重启solr之后再查询“下降”:

配置同义词转换后,查询“下降”则会返回跟“下跌”一样的结果
5. 遇到的问题
5.1 ik搜索不要加*
如果手动设置加 * 内容 *,那么星号里面的内容将不会被分词
5.2 搜索结果问题
ik 分词,对于既有文字又有数字的搜索。他的拆词是不合适的
赞助





